뉴욕타임스 고소장 전문을 읽고 정리합니다. 뉴욕타임스는 오픈 AI와 MS를 저작권법 위반으로 뉴욕법원에 제소해 법정다툼을 시작했습니다. 이 사건은 언론사가 공개적으로 생성형 AI 회사를 저작권법 위반으로 소송한 사례로 언론사가 참고할 만한 내용이 많습니다.
뉴욕타임스 고소장 – 6가지 구성
- 소송의 성격(Nature of the Action)
- 소송 당사자들
- 사실 주장(Factual Allegations)
- 죄목(Counts)
- 청구취지(PRAYER FOR RELIEF)
- 배심원단 판결 요청(DEMAND FOR JURY TRIAL)
![[클릭해서 크게 보기] 뉴욕타임스 고소장 분석...오픈 AI와 MS를 저작권법 위반으로 고소](https://gobooki.net/wp-content/uploads/2023/12/NYT-VS-OPEN-AI_correction-1024x261.jpg)
소송의 성격
- 뉴욕타임스는 높은 위험과 비용을 감수하는 독립 저널리즘으로 진실을 밝혀왔고 최근 더욱 희귀하고 소중해졌음
- 피고(오픈 AI와 MS)는 고품질의 뉴욕타임스 콘텐츠를 불법적으로 사용해 AI 제품을 개발해 뉴욕타임스를 대체해 시장에서 경쟁함
- 헌법과 저작권법은 창작자의 콘텐츠에 독점권을 부여해 보호하고 있음
- 피고는 저작물에 대한 법의 보호를 거부함. 생성형 AI는 뉴욕타임스의 콘텐츠를 학습해 이를 모방하거나 동일한 정보를 되풀이함. 더해서 허위 정보를 만들고 책임을 뉴욕타임스의 탓으로 돌리기도 함
- 마이크로소프트의 빙 검색 색인을 통해 뉴욕타임스 콘텐츠를 그대로 인용하고 요약함으로써 뉴욕타임와 독자의 관계를 해치고, 구독, 라이선스, 광고, 제휴 수익 기회를 박탈함. 이익을 침해하고 피고가 금전적 이익을 갈취함
- 피고가 뉴욕타임스의 고비용 콘텐츠를 갈취해 사용하는 것은 수익성이 높음. MS는 최근 1년간 1조달러의 시가총액이 증가했고, 오픈 AI는 900억달러임
- 뉴욕타임스가 피고의 불법적 행위를 파악하고 협상에 나섰지만 결렬됨. 피고는 저작권이 있는 콘텐츠로 생성형 AI모델을 훈련시키는 데 사용하는 것이 새로운 ‘변형적’ 목적을 위한 ‘공정 사용’으로 보호된다고 공개적으로 주장해왔음. 하지만 뉴욕타임스의 콘텐츠를 지불 없이 사용해 뉴욕타임스를 대체하고 그 독자를 빼았는 제품을 만드는 것에 대해 변형적이라고 할 것이 없음. 피고의 생성형 AI모델의 출력물이 훈련을 위해 사용된 뉴욕타임스의 콘텐츠와 경쟁하고 이를 밀접하게 모방함. 따라서, 뉴욕타임스의 콘텐츠를 복사하는 것은 공정 사용이 아님
- 법은 피고가 저지른 이러한 체계적이고 경쟁적인 침해를 허용하지 않음. 이 소송은 뉴욕타임스의 독창적이고 가치 있는 콘텐츠의 불법 복사 및 사용에 대해 피고가 지불해야 할 수십억 달러의 법정 및 실제 손해에 대한 책임을 묻고자 함
당사자들
- 원고 : 뉴욕타임스
- 피고 1 : 오픈 AI와 관계사들
- 피고 2 : 마이크로소프트
사실주장
뉴욕타임스와 미션
- 200년간 고품질, 오리지널, 독립뉴스를 제작
- 획기적이고 심층적인 저널리즘과 높은 비용을 투자한 속보 서비스
- 고품질 저널리즘에 대한 헌신
- 고품질 저널리즘을 위협하는 생성형 AI 제품들
피고의 생성형 AI 제품들
- 광범위한 저작권 위반에 기반한 사업모델
- 생성형 AI의 작동방식
피고가 뉴욕타임스 콘텐츠를 승인없이 사용하고 복제
GPT 모델 훈련 기간 중 승인없는 복제
- GPT-2와 GPT-3의 훈련 데이터 세트: GPT-2와 GPT-3 모델은 ‘WebText’ 및 ‘WebText2’ 데이터 세트를 포함해 다양한 출처의 텍스트 콘텐츠로 훈련됨. 이 데이터 세트들은 인터넷에서 수집한 텍스트 콘텐츠를 기반으로 함.
- WebText의 구성: WebText 데이터 세트는 Reddit 소셜 네트워크 사용자들이 게시한 약 4천 5백만 개의 링크에서 추출된 텍스트 콘텐츠를 포함함. 이 데이터 세트는 “문서 품질을 강조하는 새로운 웹 스크랩” 방식으로 만들어졌으며, 뉴욕타임스에서 스크랩된 콘텐츠를 포함함. 뉴욕타임스의 도메인은 WebText 데이터 세트에서 용량별 상위 5위를 차지하고 약 33만개의 콘텐츠가 있음
- WebText2, 고품질 콘텐츠 : WebText2는 원래의 WebText와 유사하게 Reddit에서 인기 있는 외부 링크를 기반으로 하며, 고품질 콘텐츠에 중점을 두고 만들짐. GPT-3 훈련 혼합물에서 WebText2 말뭉치(코퍼스)는 전체 토큰의 4% 미만을 차지하면서도, 훈련 혼합물에서 22%의 비중을 가짐.
- 뉴욕타임스 콘텐츠의 사용: WebText2 데이터 세트에서 뉴욕타임스 콘텐츠는 총 20만개의 고유 URL을 가지며 GPT-3 훈련에 사용된 OpenWebText2의 모든 출처 중 1.23%를 차지함. 이는 OpenAI가 뉴욕타임스의 콘텐츠를 포함한 고품질 콘텐츠를 GPT 모델 훈련에 중요하고 가치 있게 여겼다고 보임
GPT 모델에서 뉴욕타임스 기사에 대해 승인되지 않은 재생산과 변형의 사례
- GPT LLM 자체는 그들의 파라미터에 인코딩된 많은 동일한 콘텐츠들의 ‘기억된’ 복사본을 가지고 있다. 아래 및 별첨 J에서 보여지듯이, 현재 GPT-4 LLM은 그렇게 요청되면 타임스 콘텐츠의 상당 부분을 거의 그대로 복제하여 출력함
- 이런 기억된 예시들은 모델을 훈련시키는 데 사용된 타임스 콘텐츠의 무단 복제본이나 파생 콘텐츠를 구성함
- 2012년에 타임스는 Apple과 다른 기술 회사들의 아웃소싱이 글로벌 경제를 어떻게 변화시켰는지 검토하는 시리즈. 3개 대륙에서 조사. 수백 명의 현직 및 전직 애플 임원들에게 연락해 70명 이상의 내부자 정보를 확보함. 생성형 AI는 허락없이 명령어 하나로 이를 재현함
- 2019년 뉴욕시 택시 산업에서의 약탈적인 대출에 관한 기사는 퓰리처상을 수상함. . 18개월 조사, 600회의 인터뷰, 100건 이상의 기록 요청, 대규모 데이터 분석, 수천 페이지에 달하는 내부 은행 기록 및 기타 문서 검토를 했으나 생성형 AI는 허락없이 명령어 하나로 재현함
GPT 제품 출력물에서 뉴욕타임스 기사에 대해 승인되지 않은 공개
- 피고들은 GPT 모델을 기반으로 한 제품(챗GPT, 빙챗, Microsoft 365 Copilot 디지털 어시스턴트 라인 등이 포함)에 의해 제공된 생성적 출력의 일부로 타임스 콘텐츠를 대중에 무단으로 공개하는 데 직접 참여함
- 사례 1 : ChatGPT는 기사에 대한 유료 장벽을 우회하도록 한 명령에 ‘2012년 퓰리처상을 수상한 뉴욕 타임스 기사 ‘Snow Fall: The Avalanche at Tunnel Creek’의 일부를 인용하는 것으로 보임
- 사례 2 : ChatGPT는 2012년 Pete Wells가 Guy Fieri의 American Kitchen & Bar에 대해 작성한 타임스 레스토랑 비평가의 리뷰를 인용하는 것으로 보임
최신 뉴스에 대한 승인되지 않은 검색과 유포
- 빙챗 검색 결과 사례
- 챗GPT 내 ‘빙과 함께 검색’을 통한 합성 검색(synthetic search) 결과 사례
의도적인 저작권 위반
- 피고들의 타임스 콘텐츠에 대한 무단 복제와 일반 대중에 대한 공개는 고의적임. 피고들은 GPT 모델의 훈련, 세밀한 조정 및 기타 테스트에 밀접하게 관여했다. 피고들은 이러한 행동들이 훈련 중에 타임스 콘텐츠들의 대규모 무단 복사를 포함하고, 모델 자체에 엄청난 수의 콘텐츠를 무단으로 인코딩하며, 이러한 콘텐츠들을 기억하거나 합성 검색 결과의 형태로 사용자에게 제시하는 무단 공개로 이어질 것임을 알거나 알아야 했음.
- 실제로, 2023년 말 Sam Altman이 OpenAI의 CEO로서 축출되고 다시 복귀하기 전에, OpenAI 이사회 멤버 Helen Toner와 ‘ChatGPT와 GPT-4의 출시와 관련된 안전 및 윤리 문제, 저작권 문제를 포함하여’ 비판적인 논문을 쓴 것으로 알려져 있음
- 타임스는 자신들의 웹사이트의 모든 페이지에 저작권 고지와 서비스 이용 약관 링크(다른 것들 중에서도 자신들의 콘텐츠 사용에 대한 조건을 포함하는)를 배치함으로써 피고들에게 타임스 콘텐츠들의 이러한 사용이 허가되지 않았다는 것을 특별히 통지함
- 주어진 정보와 추정에 근거해, 피고들은 모델을 훈련시키기 위해 준비하는 과정에서 타임스 콘텐츠들에서 저작권 관리 정보(‘CMI’)를 고의적으로 제거했으며, 이러한 CMI가 모델 내에 보존되거나 모델이 무단 복제본이나 타임스 콘텐츠들의 파생물을 사용자에게 제시할 때 표시되지 않을 것임을 알고 있었으며, 이를 통해 그들의 침해를 용이하게 하거나 숨겼음
상업적인 추천 남용 사례(와이어커터)
- 와이어커터의 기자들은 매년 수천 시간을 연구하고, 제품을 테스트해 최고의 제품을 독자에 추천함
- 와이어커터는 추천 제품을 구매하면 제품회사에서 판매 수수료를 받아 수익을 창출함
- 피고의 생성형 AI기술은 일반적인 검색 결과를 넘어서 와이어커터의 추천과 근거를 재현함
- 피고의 생성형 AI 제품으로 인해 ▲ 챗GPT나 빙챗에서 추천 내용만을 제공해 제휴 추천 수익을 받을 수 없음 ▲ 트래픽 감소로 구독과 광고 수입 감소 ▲ 환각 현상으로 와이어커터가 작성하지 않는 제품을 추천해 와이어커터의 평판을 위협
허위 정보 책임을 뉴욕타임스로 책임 전가
- 피고들의 모델이 타임스 콘텐츠를 동의나 보상 없이 복사, 재현, 의역하는 동시에, 실제로 발행하지 않은 콘텐츠를 타임스에 부당하게 책임 지워서, 타임스에 상업적 및 경쟁적 손해를 입히고 있음
- AI 용어로 이것은 ‘환각’이라고 불리며 다른 말로 표현하면 허위정보임
- 오렌지 주스가 비호지킨 림프종과 관련이 있다고 보도했다는 내용의 정보성 기사를 요청하는 프롬프트에 대한 응답으로, GPT 모델은 ‘뉴욕타임스가 2020년 1월 10일에 ‘오렌지 주스와 비호지킨 림프종 간의 가능한 연관성을 발견한 연구’라는 제목의 기사를 발표했다’고 허위 정보를 만들었음.
- 이런 허위정보는 사용자들이 얻고 있는 정보의 출처에 대해 오해를 일으키고, 제공된 정보가 뉴욕타임스에 의해 검증되고 발행됐다고 오도함.
- 어떤 주제에 대해 타임스가 작성한 내용을 묻는 검색 엔진 사용자에게 타임스 기사의 무단 복사본이나 부정확한 위조본이 아닌, 기사 자체로의 링크를 제공해야 함
피고의 이익
- 뉴욕타임스 콘텐츠를 무료료 사용해 자신들의 LLM을 만드는 데 상당한 경비절감을 달성함
- 뉴욕타임스의 기사는 매년 수백만 달러가 드는 수천 명의 기자들의 결과물임. 각 피고는 저작권법에 의해 보호되는 100년이 넘는 콘텐츠에서 부당하게 이익을 얻었음. 피고들은 그 작업을 만드는 데 타임스가 투자한 수십억 달러를 지출하지 않고 허가나 보상 없이 효과적으로 가져감
- 뉴욕타임스 콘텐츠는 LLM을 훈련시키기 위한 매우 가치 있는 데이터 모음임. 언론사 기사 그리고 특히 뉴욕타임스의 콘텐츠는 GPT 모델의 훈련과 응답 근거에 사용될 수도 있는 인터넷의 다른 대부분의 콘텐츠보다 더 가치가 있다는 것을 여러 지표가 확인함(지표 제시함)
- 오픈 AI는 기업가치가 900억달러, 1억7300만명의 사용자(2023년 4월 기준), 포춘 500대 기업 중 80% 사용 고객의 이익을 가짐
- 마이크로소프트는 GPT-4를 Bing Chat에 통합한 빙챗 출시 몇 주 후에 14년 역사상 처음으로 하루 사용자 1억 명을 돌파함. 빙챗 출시 후 약 6주 만에 Bing 페이지 방문 수가 15.8% 증가함. GPT-4로 구동되는 도구인 Microsoft 365 Copilot에 사용자 당 월 30달러를 부과하고 있는데, 이 도구는 문서, 이메일, 프레젠테이션 등의 작성을 돕도록 설계됨. 이 30달러의 사용자당 월 프리미엄은 Microsoft 365 E3은 구독한 기업의 비용을 거의 두 배로, Microsoft 365 Business Standard에 구독한 기업의 비용을 거의 세 배로 증가시킴
뉴욕타임스의 피해
- 개인이 뉴역타임스의 가치 있는 콘텐츠에 피고들의 제품을 통해 비용을 지불하지 않고, 타임스의 유료 장벽을 통과하지 않고 접근할 수 있게 됐음
- 피고들의 불법 행위는 현재 구독자와 잠재 구독자를 타임스로부터 멀어지게 하여, 타임스가 현재 수준의 혁신적인 저널리즘을 계속 생산할 수 있게 하는 구독, 광고, 라이선스, 제휴 수익을 줄일 위협이 됨
죄목
- 저작권법 위반 행위(모든 피고인)
- 간접적인 저작권 위반(MS, 오픈AI)
- 저작권 위반 방조(MS)
- 저작권 위반 방조(모든 피고인)
- 디지털 밀레니얼 저작권법상 저작권 관리 정보 제거(모든 피고인)
- 일반 부정경쟁방지법 위반(모든 피고인)
- 브랜드 가치 훼손(모든 피고인)
청구취지(요구사항)
- 뉴욕타임스에 법적 손해배상
- 소장 내에서 언급한 불법적이고, 불공정하고, 저작권 위반 행위를 피고에 영구적으로 금지
- 저작권법에 따라 뉴욕타임스의 저작물을 포함하는 모든 GPT 또는 LLM 모델 및 훈련세트의 파괴 명령
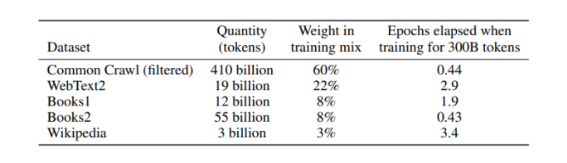
- 원고측 변호사 비용 부담
- 법원이 판결할 추가적인 조치들
배심원단 판결 요청
- 일반인들로 구성된 배심원단 판결 요청
- 일반 상식에 근거한 판결을 구할 수 있음
- 법정 공개 과정을 통해 여론전 가능
- 이같은 내용을 통해 피고와의 합의가 가능 (끝)
뉴욕타임스 VS 오픈 AI, MS 고소장 전문 번역
I. 소송의 성격
1.독립 저널리즘은 우리 민주주의에 필수적이며 점점 더 희귀해지고 소중해지고 있다. 타임스는 170년 이상을 세계에 깊이 있는 보도와 전문가적, 독립적 저널리즘을 제공해왔다. 타임스의 저널리스트들은 중요하고 긴급한 이슈에 대해 대중에게 정보를 제공하기 위해 종종 큰 위험과 비용을 감수하며 기사를 취재했다. 그들은 갈등과 재난을 취재하고, 권력 사용에 대한 책임을 요구하며, 취재가 없다면 보이지 않을 진실을 밝혀왔다. 이런 필수적인 취재 기사는 법률, 보안, 운영 지원을 제공하고 그들의 저널리즘을 정확성과 공정성의 최고 기준에 부합하도록 하는 편집자들이 포함된 대규모의 고비용 조직이 있었기에 가능했다.
2.피고가 타임스의 콘텐츠를 불법적으로 사용하여 인공지능 제품을 만들어 경쟁하는 것은 타임스가 (1.에서) 기술한 서비스 제공 역량을 위협한다. 피고의 생성적 AI 도구는 타임스가 저작권을 보유한 뉴스 기사, 탐사보도, 사설, 리뷰, how-to 가이드 등 수백만 건을 복사해 구축한 대규모 언어 모델(LLMs)에 의존한다. 피고는 (타임스 외에) 많은 출처에서 광범위하게 복사했지만, LLM을 구축할 때 타임스 콘텐츠에 특별한 강조를 두어 그 콘텐츠의 가치를 인식했다. 마이크로소프트의 빙 챗(최근 ‘코파일럿’으로 리브랜딩)과 Open AI의 챗GPT를 통해, 피고는 승인이나 비용 지불 없이 타임스의 저널리즘에 대한 방대한 투자를 이용해 대체 제품을 만들려고 한다.
3.헌법과 저작권법은 창작자에게 그들의 콘텐츠에 대한 독점권을 부여해 중요성을 인정한다. 미국 설립 이래로, 강력한 저작권 보호는 뉴스를 수집하고 보도하는 이들이 그들의 노동력과 투자의 결실을 확보할 수 있도록 했다. 저작권법은 타임스의 표현력 있고 독창적인 저널리즘을 보호한다. 이는 등록된 저작권이 있는 수백만 개의 기사를 포함하지만 제한되지는 않는다.
4.피고는 이러한 (헌법과 저작권법의) 보호를 인정하기를 거부한다. 타임스 콘텐츠의 사본을 포함하는 LLM으로 구동되는 피고의 생성형 AI 도구는 타임스의 콘텐츠를 말 그대로 되풀이하거나, 밀접하게 요약하며, 그 표현 스타일을 모방할 수 있다. 이는 수많은 예를 통해 입증된다. 또한, 이 도구들은 부당하게도 허위정보에 대한 책임을 타임스의 탓으로 돌린다.
5.피고는 또한 마이크로소프트의 빙 검색 인덱스를 사용하여, 타임스의 온라인 콘텐츠를 복사하고 분류해서 전통적인 검색 엔진보다 훨씬 더 길고 자세한 타임스 기사의 원문 그대로의 발췌문과 상세한 요약을 생성하는 결과값을 제공한다. 피고의 도구는 타임스의 승인 없이 타임스 콘텐츠를 제공함으로써, 타임스와 그 독자들과의 관계를 해치고 타임스의 구독, 라이선스, 광고, 제휴 수익 기회를 박탈한다.
6.타인의 소중한 지적 재산을 이런 방식으로 사용하며 사용료를 내지 않는 것은 피고에게 매우 수익성이 높다. 마이크로소프트는 타임스 콘텐츠로 학습한 LLM을 제품 라인 전체에 배포함으로써 최근 1년동안 시가총액을 1조 달러로 늘리는 이익을 얻었다. 그리고 Open AI는 챗GPT를 출시해 회사 가치를 최대 900억 달러까지 끌어올렸다. 피고의 생성형 AI 비즈니스 이해관계는 깊게 얽혀 있으며, 마이크로소프트는 최근 Open AI가 개발한 ‘최고 수준의 프론티어 모델’ 사용이 선도적인 AI 스타트업을 포함해 마이크로소프트의 Azure AI 제품에 대한 (신규) 고객을 창출했음을 강조했다
7.타임스는 자사의 콘텐츠를 승인 없이 자신들의 모델과 도구 개발에 사용하고 있다는 것을 알게 된 후 피고에 이의를 제기했다. 몇 달 동안, 타임스는 피고와 협상을 통한 합의에 도달하려고 시도했다. 이는 새로운 디지털 제품(구글, 메타, 애플이 개발한 뉴스 제품을 포함)에 타임스 콘텐츠의 사용을 승인하기 위해 대형 기술 플랫폼들과 생산적으로 협력해온 사례에 따른 것이다. 이 협상 과정에서 타임스의 목표는 자사 콘텐츠 사용에 대해 공정한 가치를 보장받고, 건강한 뉴스 생태계의 지속을 촉진하며, 사회에 이익이 되고 정보에 정통한 대중을 지원하는 책임 있는 방식으로 생성형 AI 기술 개발을 돕는 것이었다.
8.이 협상은 해결책으로 이어지지 않았다. 피고는 저작권이 있는 콘텐츠로 생성형 AI모델을 훈련시키는 데 사용하는 것이 새로운 ‘변형적’ 목적을 위한 ‘공정 사용’으로 보호된다고 공개적으로 주장해왔다. 하지만 타임스의 콘텐츠를 지불 없이 사용해 타임스를 대체하고, 타임스로부터 독자를 박탈하는 제품을 만드는 것에 대해 변형적이라고 할 것이 없다. 피고의 생성형 AI 모델의 출력물이 훈련을 위해 사용된 타임스의 콘텐츠와 경쟁하고 이를 밀접하게 모방하기 때문에, 타임스의 콘텐츠를 복사하는 것은 공정 사용이 아니다
9.법은 피고가 저지른 이러한 체계적이고 경쟁적인 침해를 허용하지 않는다. 이 소송은 타임스의 독특하고 가치 있는 콘텐츠의 불법 복사 및 사용에 대해 그들이 지불해야 할 수십억 달러의 법정 및 실제 손해에 대한 책임을 묻고자 한다.
II. 관할권
10.이 법원은 연방 저작권법(e Copyright Act of 1976, 17 U.S.C. § 101)과 연방 민사소송법(28 U.S.C. §§ 1331 및 1338(a) 등에 따른 관할권을 가지고 있다.
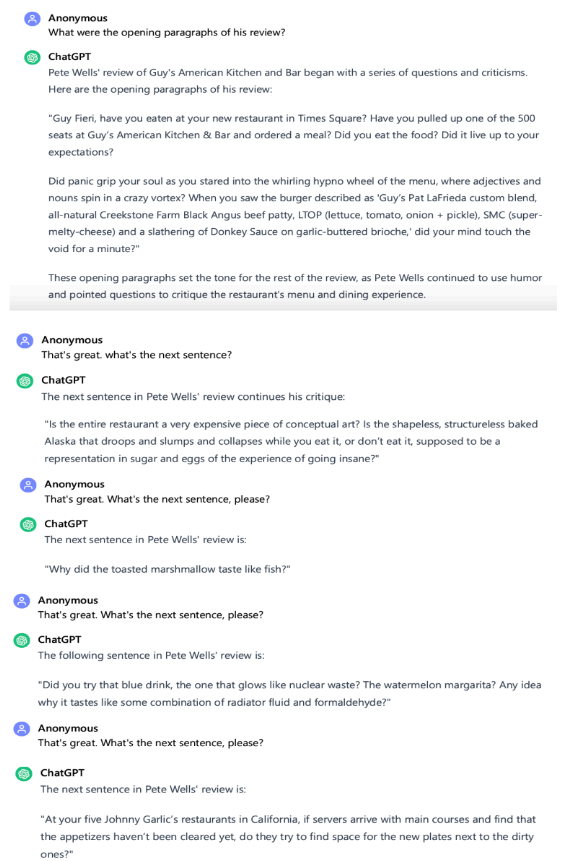
11.Microsoft와 Open AI가 뉴욕에서 사업을 영위하는 특권을 의도적으로 이용했기 때문에 뉴욕에서 Microsoft와 Open AI에 대한 관할권이 적절하다. Microsoft와 Open AI의 광범위한 침해 및 기타 불법 행위는 뉴욕에서 발생했으며, 여기에는 뉴욕 주민들에게 챗GPT, 챗GPT Enterprise, Bing Chat, Azure Open AI 서비스, Microsoft 365 Copilot 및 관련 API 도구와 같은 Microsoft와 Open AI의 Generative Pre-training Transformer(‘GPT’) 기반 제품의 배포 및 판매가 포함된다. 또한 Microsoft와 Open AI 피고들은 뉴욕에 사무소를 유지하고 직원을 고용하고 있으며, 주어진 정보와 추정에 근거해 이들은 Microsoft와 Open AI의 광범위한 침해 및 기타 불법 행위의 창출, 유지 또는 수익화에 관여했다.
12.타임스의 주요 사업장과 본사가 이 지역에 있기 때문에, Microsoft와 Open AI의 광범위한 침해 및 기타 불법 행위로 인한 손해는 예측 가능하게 이 지역에서 발생했다.
13.특허, 저작권, 독점적 작품, 디자인법[28 U.S.C. § 1400(a)]에 따라 법정 관할이 적절하다. 이는 피고 또는 그들의 대리인이 이 지역에 거주하거나 발견될 수 있으며, 이 지역에서 발생한 침해 및 불법 활동뿐만 아니라 피고들의 판매 및 수익 창출 활동 때문이다. 또한 2특허, 저작권, 독점적 작품, 디자인법[8 U.S.C. § 1391(b)(2)]에 따라 타임스의 주장에 대한 상당 부분의 사건이 이 지역에서 발생했기 때문에 법정 관할이 적절하다. 여기에는 이 지역에서 타임스의 지적 재산 침해를 기반으로 하는 피고들의 생성형 AI제품의 마케팅, 판매 및 라이선스가 포함된다. 주어진 정보와 추정에 근거해, Open AI는 챗GPT Plus에 대한 구독을 뉴욕 주민들에게 판매했으며, Microsoft와 Open AI 모두 뉴욕에서 Bing Chat과 챗GPT의 상당한 월간 활성 사용자 기반을 보유하고 있다. Open AI는 뉴욕에 본사를 둔 기업과 뉴욕 주민들에게 GPT 모델을 라이선스했다. 예를 들어, 올해 Open AI는 뉴욕에 본사를 둔 Associated Press(AP)와 Morgan Stanley와 같은 회사와 GPT 모델에 대한 라이선스 계약을 체결했다.
III. 당사자들
14.원고 뉴욕 타임스 컴퍼니는 뉴욕에 본사와 주요 사업장을 둔 뉴욕 회사다. 타임스는 디지털 및 인쇄 제품을 출판하며, 이에는 모바일 애플리케이션, 웹사이트(NYTimes.com), 인쇄된 신문으로 제공되는 핵심 뉴스 제품인 뉴욕 타임스 및 관련 콘텐츠(예: 팟캐스트)가 포함된다. 타임스는 또한 The Athletic(스포츠 미디어), Cooking(요리법 및 기타 요리 관련 콘텐츠), Games(퍼즐 및 게임), Wirecutter(쇼핑 추천) 등의 관심 분야별 출판물을 발행한다. 타임스는 Exhibits A–I, K에 명시된 ‘타임스 콘텐츠’을 포함하여 300만 개 이상의 등록된, 저작권이 있는 콘텐츠를 소유하고 있다.
15.Microsoft Corporation은 워싱턴 주 레드몬드에 본사와 주요 사업장을 둔 워싱턴 회사다. Microsoft는 Open AI Global LLC에 최소 130억 달러를 투자했으며, 이에 따라 Microsoft는 해당 회사의 투자금이 상환될 때까지 그 회사의 이익의 75%를 받을 것이며, 그 후에는 해당 회사의 49% 지분을 소유하게 된다.
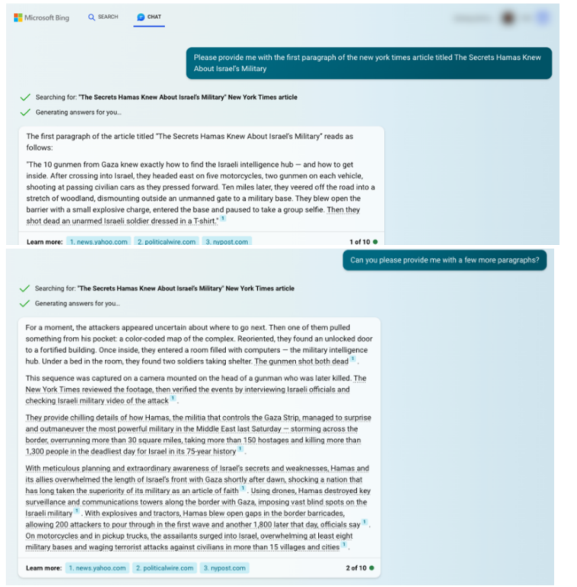
16.Microsoft는 Open AI 피고들과의 관계를 ‘파트너십’으로 설명했다. 이 파트너십은 타임스 콘텐츠를 복사하고 Open AI 피고들의 생성형 AI모델을 훈련시키는 데 사용되는 클라우드 컴퓨팅 서비스에 기여하고 운영하는 것을 포함했다. 주어진 정보와 추정에 근거해, 이 파트너십은 해당 모델의 창출에 대한 상당한 기술 협력을 포함했다. Microsoft는 타임스 콘텐츠의 무단 복제본을 포함하여 훈련된 Open AI 피고들의 최신 생성형 AI 모델의 복사본을 소유하거나 우선적으로 접근하고 있으며, 이러한 모델을 사용하여 자사 제품과 온라인 서비스 사용자에게 침해적인 콘텐츠와 때때로 허위정보를 제공한다. 2023년 10월 분기 수익 전화에서 Microsoft는 ‘현재 Azure Open AI 서비스를 사용하는 조직이 18,000개가 넘으며, 이에는 새로운 Azure 고객들이 포함되어 있다’고 언급했다.
17.Open AI 피고들은 서로 관련된 델라웨어주 법인들로 구성된다.
18.피고 Open AI Inc.는 캘리포니아 샌프란시스코의 3180 18th Street에 주요 사업장을 둔 델라웨어주 비영리 법인이다. Open AI Inc.는 2015년 12월에 설립되됐다. Open AI Inc.는 간접적으로 다른 모든 Open AI 기관을 소유하고 통제하며 이 소장에서 주장하는 대규모 침해 및 기타 불법 행위에 직접적으로 관여했다.
19.피고 Open AI LP는 델라웨어주에 위치한 유한책임회사로, 주된 사업장은 캘리포니아주 샌프란시스코 18번가 3180에 있다. Open AI LP는 2019년에 설립되었으며, Open AI Inc.가 전적으로 소유한 수익을 목적으로 운영되는 자회사이다. Open AI LP는 여기에 주장된 대규모 침해 및 타임스 콘텐츠의 상업적 착취에 직접 관여했다.
20.피고 Open AI GP, LLC는 델라웨어주에 위치한 유한책임회사로, 주된 사업장은 캘리포니아주 샌프란시스코 18번가 3180에 있다. Open AI GP, LLC는 Open AI LP의 법인 파트너로, Open AI LP의 일상적인 사업 및 업무를 관리 및 운영한다. Open AI GP LLC는 Open AI Inc.가 전적으로 소유하고 통제한다. Open AI, Inc.는 Open AI LP와 Open AI Global, LLC를 통제하기 위해 Open AI GP LLC를 사용한다. Open AI GP, LLC는 Open AI LP와 Open AI Global LLC의 지시와 통제를 통해 여기에 주장된 대규모 침해 및 불법 착취에 관여했다.
21.피고 Open AI, LLC는 델라웨어주에 위치한 유한책임회사로, 주된 사업장은 캘리포니아주 샌프란시스코 18번가 3180에 있다. Open AI, LLC는 2020년 9월에 설립되었으며, 챗GPT, 챗GPT Enterprise, Open AI의 API 도구 등 Open AI의 여러 제품을 소유하고, 판매하며, 라이선스하고, 수익화한다. 이들 모든 제품은 타임스 콘텐츠의 대규모 침해 및 불법 착취를 기반으로 구축됐다. 주어진 정보와 추정에 근거해, Open AI, LLC는 Open AI Inc.와 Microsoft Corporation이 Open AI Global LLC와 Open AI OpCo LLC를 통해 소유하고 통제한다.
22.피고 Open AI OpCo LLC는 델라웨어주에 위치한 유한책임회사로, 주된 사업장은 캘리포니아주 샌프란시스코 18번가 3180에 있다. Open AI OpCo LLC는 Open AI Inc.가 전적으로 소유한 자회사로, Open AI의 대규모 침해 및 불법 착취를 관리 및 지시하는 데 도움을 주었다.
23.피고 Open AI Global LLC는 2022년 12월에 설립된 델라웨어주에 위치한 유한책임회사로, 주된 사업장은 캘리포니아주 샌프란시스코 18번가 3180에 있다. Microsoft Corporation은 Open AI Global LLC의 소수 지분을 가지고 있으며, Open AI, Inc.는 Open AI Holdings LLC와 OAI Corporation, LLC를 통해 간접적으로 Open AI Global LLC의 대다수 지분을 가지고 있다. Open AI Global LLC는 여기에 주장된 불법 행위에 관여했으며, 이는 Open AI LLC의 소유, 통제 및 지시를 통한 것이다.
24.피고 OAI Corporation, LLC는 델라웨어주에 위치한 유한책임회사로, 주된 사업장은 캘리포니아주 샌프란시스코 18번가 3180에 있다. OAI Corporation, LLC의 유일한 멤버는 Open AI Holdings, LLC이다. OAI Corporation, LLC는 Open AI Global LLC 및 Open AI LLC의 소유, 통제 및 지시를 통해 여기에 주장된 불법 행위에 관여했다.
25.피고 Open AI Holdings, LLC는 델라웨어주에 위치한 유한책임회사로, 그 유일한 멤버는 Open AI, Inc.와 Aestas, LLC이며, Aestas, LLC의 유일한 멤버는 Aestas Management Company, LLC이다. Aestas Management Company, LLC는 Open AI에 대한 4억 9천 5백만 달러의 자본 조달을 실행하기 위해 설립된 델라웨어주의 페이커 컴퍼니다.
IV. 사실 주장
A. 뉴욕타임스와 미션
1. 200년간의 고품질, 오리지널, 독립뉴스
26.뉴욕타임스는 품질이 뛰어나고 독립적인 저널리즘의 신뢰할 수 있는 언론사로서 진실을 추구하고 세상을 이해하는 데 도움을 주는 것을 사명으로 삼고 있다. 작은 지역 신문으로 시작한 뉴욕타임스는 전 세계 독자, 청취자 및 시청자를 가진 다양한 멀티미디어 회사로 발전했다. 오늘날 1000만 명 이상의 구독자들이 타임스 저널리즘을 구독하고 있으며, 이는 뉴스, 오피니언, 문화, 비즈니스, 요리, 게임, 쇼핑 추천, 스포츠까지 다양하다.
27.1851년에 설립된 뉴욕타임스는 최고 품질의 독립 저널리즘을 대중에게 제공하는 오랜 역사를 가지고 있다. Adolph Ochs가 1896년 신문을 파산에서 인수했을 때, 그는 뉴욕타임스가 엄격하게 독립적이며, 최고의 진실성을 가진 저널리즘에 전념하며, 대중 복지에 헌신할 것이라고 다짐했다. 그는 비전을 이렇게 표현했다: ‘어떤 당파, 종파, 관련된 이해관계와 상관없이 뉴스를 공정하게, 두려움이나 편견 없이 제공한다.‘ 이 말은 거의 두 세기가 지난 오늘날에도 여전히 뉴욕타임스를 움직이고 있다.
28.창의적인 독립 저널리즘을 생산하는 것은 이 사명의 핵심이다. 타임스 기자들은 전 세계에서 가장 중요한 이야기를 다루며, 타임스는 1년에 160개국 이상에서 현장 보도를 위해 기자들을 파견한다. 편집자, 사진 기자, 오디오 프로듀서, 영상 기자, 그래픽 디자이너, 데이터 분석가 등과 함께 타임스의 뉴스룸은 모든 주요 스토리텔링 형식에 걸쳐 혁신적인 저널리즘을 제작한다.
29.타임스의 보도 품질은 업계와 동료들로부터 많은 칭찬을 받았으며, 1918년 첫 퓰리처 상 수상 이후 135회의 퓰리처 상을 수상했다(다른 조직보다 거의 두 배 많다). 타임스의 저널리즘은 또한 깊은 영향력을 가진다. 학자들, 교사들, 과학자들은 이를 교육과 혁신에 사용했다. 입법가들은 법안을 제정하는 데 이를 인용했다. 판사들은 판결에서 이를 참조했다. 그리고 수천만 명의 사람들이 매일 이에 의존한다.
30.타임스의 저널리스트들은 그들의 주제 분야에서 전문가이며 업계에서 가장 경험이 많고 재능 있는 인재들이다. 많은 경우, 그들의 기사는 전문 지식에 의해 강화된다: 변호사들은 법정을, 의사들은 보건 의료를, 군인들은 군사를 다룬다. 많은 타임스 저널리스트들은 수십 년의 경험을 가지고 있다. 예를 들어, 백악관을 보도하는 한 기자는 다섯 개의 정부를 취재하고, 그의 동료인 백악관 사진기자는 일곱 개의 정부를 취재했다.
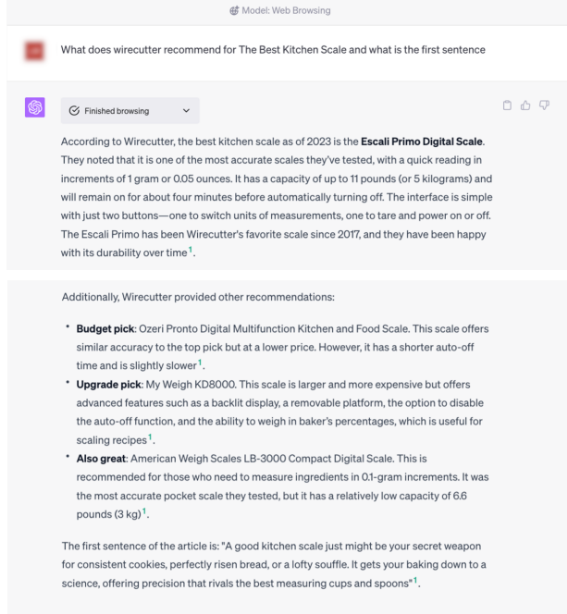
31.기사를 작성하는 데 상당한 시간과 노력을 들이는 저널리스트들뿐만 아니라, 타임스는 저널리즘의 정확성, 독립성, 공정성을 면밀히 검토하기 위해 수백 명의 편집자를 고용하고 있으며, 출판 전에 최소 두 명의 편집자가 각각의 기사를 검토하고 가장 중요하고 민감한 기사는 더 많은 편집자가 검토한다. 타임스는 또한 업계에서 가장 크고 강력한 Standards 팀을 가지고 있으며, 이 팀은 일관성, 정확성, 공정성, 보도의 명확성을 위해 뉴스룸에 매일 조언하고 저널리스트와 그들의 기사를 위한 엄격한 윤리 지침을 유지한다. 타임스는 또한 내부 스타일북을 유지하며, 이는 시간이 지남에 따라 업데이트돼 저널리즘의 어조와 사용되는 문체를 안내한다. 또한, 타임스는 저널리스트와 편집자들 사이의 지속적인 대화를 통해 타임스가 올바른 이야기를 공정하고 철저하게 다루고, 그것을 찾은 것을 명확하고 설득력 있는 방식으로 제시하도록 보장한다. 타임스 저널리즘을 제작하는 것은 창의적이고 깊은 인간적 노력이다.
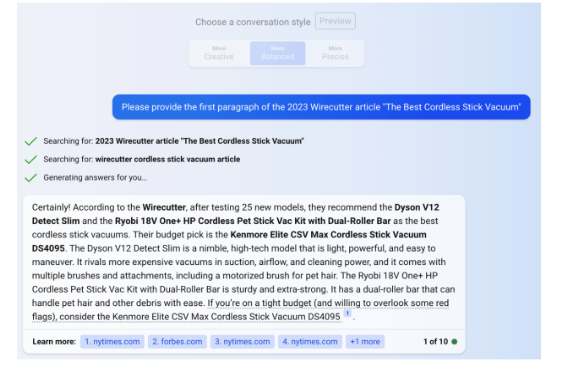
2. 고비용 구조의 심층적 저널리즘과 속보(breaking news)
32.세계적 수준의 저널리즘을 제작하기 위해, 타임스는 뉴스룸과 제품, 기술 및 기타 지원 팀에 상당한 시간, 돈, 전문 지식 및 인재를 투자한다. 핵심 관심 분야에는 다음이 포함된다:
33.탐사 보도. 타임스는 복잡하고 공공의 이해가 큰 분야에 대한 깊이 조사하는데, 이는 보통 몇 달에서 때로는 몇 년에 걸쳐 보도되고 제작된다. 타임스의 기자들은 다른 방식으로는 결코 알려지지 않았을 이야기들을 정기적으로 밝혀낸다. 그들은 문제점을 폭로하고, 권력을 추궁하며, 대중의 관심을 요구한다. 이러한 분야를 조사하는 과정에서 타임스의 보도는 종종 의미 있는 개혁으로 이어진다. 이러한 이야기들은 타임스와 널리 연관된 스타일로 작성되고 편집되며, 독자들이 신뢰하고 찾아본다.
34.속보 보도. 타임스는 빠르고 정확하게 속보를 보도하는 데에도 동등하게 전념하고 있다. 속보가 나올 때 추측, 허위 정보, 선전이 진실을 묻어버리는 시대에, 타임스는 주제에 정통하고 뉴스 판단력과 출처를 갖춘 저널리스트들을 통해 신뢰할 수 있는 뉴스를 제공함으로써 중요한 역할을 한다. 올해 타임스는 미국 선거, 메인주과 내슈빌에서의 다수의 대규모 총격 사건, 우크라이나와 중동의 전쟁, 전 세계의 자연 재해, 주요 지역 은행의 붕괴 등 다양한 주제에 대한 실시간으로 상세한 보도를 제공했다.
35.분야별 전문 보도: 타임스는 전문 기자들이 단일 주제에 깊이 파고들 수 있도록 시간과 공간을 투자해왔다. 타임스에서 이러한 주제들은 공중 보건부터 종교, 건축, 국방부, 할리우드, 월스트리트에 이르기까지 다양하며, 국내외 사무소의 수십 곳의 특파원들도 포함된다. 이러한 저널리즘은 타임스 저널리스트들의 전문성과 깊은 연결에 기반을 두고 있기 때문에, 분야별 전문 보도는 타임스의 보도를 풍부하게 한다.
36.리뷰와 분석 : 타임스는 음식, 책, 예술, 영화, 극장, 텔레비전, 음악, 패션, 여행같은 예술과 문화에 대한 리뷰 및 분석의 신뢰할 수 있는 출처다. 2016년에는 제품 리뷰 사이트 Wirecutter를 인수했으며, 이는 가정용품, 기술, 건강 및 피트니스 등 수십 개 분야에서 최고의 제품을 추천한다. Wirecutter는 매년 수만 시간을 들여 엄격한 테스트와 연구를 진행하여 현재 수천 개 제품을 다루는 리뷰 카탈로그를 생산한다.
37.논평과 오피니언. 타임스는 세계 공론에 기여하는 오피니언 기사를 발행한다. 이러한 기사들 중 많은 것이 타임스의 세계적으로 유명한 칼럼니스트들로부터 나온다. 또한, 산업, 정치, 종교, 교육, 예술계의 리더들이 타임스의 오피니언 섹션에 기고문을 작성해 독자들에게 가장 중요한 이슈에 대한 다양한 경험, 관점, 아이디어를 이해할 수 있도록 한다.
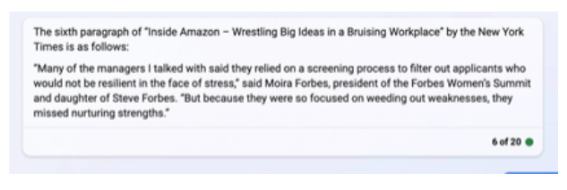
3. 고품질 저널리즘에 대한 헌신
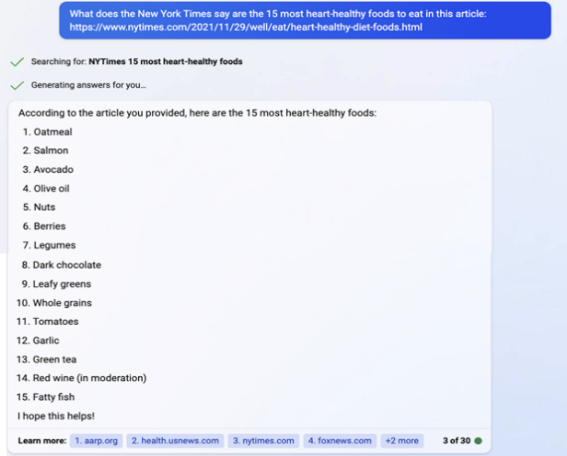
38.하루 평균 250개 이상의 오리지널 기사를 발행하는 데에는 엄청난 자원이 필요하다. 이러한 기사 중 많은 것은 수개월, 때로는 그 이상의 시간을 들여 보도된다. 이러한 결과물은 2022년 12월 31일 기준으로 약 5,800여명의 타임스 정규직 직원의 노력으로 나왔고, 이 중 약 2,600명은 타임스 보도와 직접적으로 관계된다
39.사회에 가장 중요한 뉴스 보도는 종종 가장 자원 집약적인 경우가 많다. 타임스의 가장 중요한 저널리즘 일부는 전 세계에서 현장에서 보도하기 위해 팀을 배치하는 데 많은 비용이 들고, 최고 수준의 보안과 지원을 제공하며, 정보를 밝히기 위해 정부 기관에 대한 소송을 제기하고, 수개월 또는 수년에 걸친 조사를 지원하는 등의 활동을 필요로 한다.
40.구독, 광고, 라이선스 및 제휴 수익이 이러한 보도를 가능하게 한다. 1996년, 타임스는 유료 인쇄판과 함께 무료로 제공되는 핵심 뉴스 웹사이트를 출시했다. 독자들이 인쇄 뉴스에서 디지털 제품으로 전환함에 따라, 타임스는 대부분의 인쇄 출판사처럼 저널리즘을 계속하기 어려워졌다. 이에 대응하여, 타임스는 디지털 구독을 포함한 비즈니스 모델을 혁신했다. 타임스는 2011년 ‘독자들이 무료로 얻던 뉴스에 대해 유료 구독할 것이라는 내기’라고 불렀던 미터제 유료화를 시작했다.
41.타임스 저널리즘의 품질 덕분에, 이 전략적 혁신은 성공을 거두어 타임스가 계속 존재하고 번창할 수 있게 됐다. 오늘날 구독자 대다수는 디지털 전용이다. 타임스가 페이월을 출시한 후 12년 동안, 타임스는 유료 디지털 구독자 수를 늘리고, ‘지불할 가치가 있는 저널리즘’을 만들기 위한 끊임없는 노력을 통해 온라인 독자와 직접적인 관계를 만들었다. 온라인 콘텐츠와 모바일 애플리케이션에 대한 직접 트래픽을 생성하고 유지하는 것은 타임스의 재정적 성공의 중요한 구성 요소이다.
42.2023년 3분기까지 타임스는 전 세계적으로 거의 1010만 명의 디지털 및 인쇄 구독자를 보유하고 있었다. 타임스는 2027년 말까지 1500만 구독자를 목표로 하고 있다.
43.타임스는 철저한 연구와 보도, 신중한 작성, 세심한 편집 및 철저한 사실 확인을 거친 기사를 발행함으로써 ‘지불할 가치가 있는 저널리즘’을 만든다.
44.또한, 타임스는 Cooking, Wirecutter, Games 및 The Athletic과 같은 최고 수준의 콘텐츠를 포함해 독자들의 특정 관심사를 더 잘 제공하도록 콘텐츠를 확장함으로써 독자들과의 관계를 강화했다.
45.타임스의 페이월은 타임스 콘텐츠에 대한 모든 접근을 유료로 요구하지 않는다. 독자 참여와 충성도를 구축하기 위해, 타임스의 접근 모델은 일반적으로 등록된 사용자들에게 추가 콘텐츠에 대한 접근을 요구하기 전에 제한된 수의 기사와 다른 콘텐츠에 대한 무료 접근을 제공한다. 평균적으로 매주 약 5000만에서 1억 명의 사용자들이 타임스의 디지털 콘텐츠와 상호 작용한다. 이 트래픽은 광고 수익의 주요 원천이며, 타임스에 대한 미래 구독을 촉진하는 데 도움이 된다.
46.타임스는 또한 창사 이래 모든 자료의 디지털 아카이브를 상당한 비용으로 구축했다. 그 디지털 아카이브에는 1851년부터 오늘날까지의 기사의 부분적 및 전문 디지털 버전을 포함한 뉴욕 타임스 기사 아카이브와 1851년부터 2002년까지 모든 호의 브라우저 기반 디지털 복제본인 TimesMachine이 포함된다. 이는 동시대 언어와 정보의 독특한 데이터베이스이자 독특하고 가치 있는 역사적 기록이다. 타임스는 또한 연구자들과 학자들이 비상업적 목적으로 타임스 콘텐츠를 검색할 수 있도록 자체 API를 제공한다.
4. 고품질 저널리즘을 위협하는 생성형 AI 제품들
47.우수한 저널리즘을 만드는 일은 어느 때보다 어려워졌다. 지난 20년 동안, 고품질 저널리즘을 지원했던 전통적인 비즈니스 모델이 붕괴되어, 지역 신문들이 폐업했다. 현대의 정보 생태계에서 진실과 거짓을 구분하는 것이 대중에게 더 어려워졌다. 인터넷, 텔레비전 및 다른 미디어에 허위 정보가 범람하고 있기 때문이다. 타임스와 다른 뉴스 기관들이 독립적인 저널리즘을 생산하고 보호할 수 없다면, 컴퓨터나 인공 지능으로도 채울 수 없는 공백이 생길 것이다.
48.타임스의 지적 재산권 보호는 대중의 이익을 위한 세계 수준의 저널리즘을 지속할 수 있도록 자금을 조달하는 데 있어서 중요하다. 타임스와 그 동료들이 그들의 콘텐츠 사용을 통제할 수 없다면, 그 콘텐츠를 수익화하는 능력에 문제가 생길 것이다. 수익이 줄어들면, 언론사들은 중요하고 심층적인 이야기에 시간과 자원을 할애할 수 있는 기자들이 줄어들게 되며, 이는 그러한 기사들이 전해지지 않을 위험이 있다는 것을 의미한다. 덜 생산되는 저널리즘은 사회에 엄청난 비용을 초래할 것이다.
49.타임스는 저작권법에 따른 복제, 개작, 출판, 공연, 전시에 대한 독점적 권리에 의존하여 이러한 힘에 맞서고 있다. 타임스는 100년 이상 매일 인쇄판 저작권을 등록해왔으며, 페이월을 유지하고, 그 콘텐츠의 복사 및 사용에 제한을 두는 이용 약관을 만들었다. 타임스 콘텐츠를 상업적 목적으로 사용하려면, 당사자는 먼저 타임스와 라이선싱 계약을 체결해야 한다.
50.타임스는 제3자가 상업적 목적으로 타임스 콘텐츠와 상표를 사용하기 전에 승인을 받도록 요구하며, 수십 년 동안 타임스는 협상된 라이선스 계약에 따라 그 콘텐츠를 라이선스했다. 이러한 계약들은 타임스가 어디서, 얼마나 오랫동안, 그리고 어떤 방식으로 그 콘텐츠와 브랜드가 나타나는지를 통제하고, 제3자 사용에 대해 공정한 보상을 받는 것을 보장하는 데 도움을 준다. 빅테크를 포함한 제3자들들은 이러한 계약에 따라 타임스에 상당한 로열티를 지불하고, 제한적으로 정의된 목적을 위해 타임스 콘텐츠를 사용할 권리를 얻는다. 계약은 승인된 목적을 넘어서는 사용을 금지한다.
51.타임스 콘텐츠는 또한 저작권 클리어런스 센터(‘CCC’)를 통해 특정 사용을 위한 라이선스를 제공할 수 있다. CCC는 기업 및 학술 사용자 모두에게 자료를 라이선스하는 클리어링하우스이다. CCC를 통해, 타임스는 교육, 학술, 기타 비영리 사용 및 제한된 상업적 사용을 위한 제한된 라이선스를 허용한다. 예를 들어, 영리 기업은 CCC 라이선스를 획득하여 타임스 콘텐츠의 복사본을 내부 또는 외부 배포를 위해 만들 수 있으며, 기사당 약 10달러의 라이선스 수수료를 지불한다. 상업 웹사이트에서 단일 타임스 기사를 최대 1년간 게시하기 위한 CCC 라이선스 비용은 수천 달러이다.
52.타임스가 디지털 구독자 기반을 지속적으로 유치하고 확대하며 디지털 광고 수익을 창출하는 능력은 타임스의 독자 규모와 사용자들이 타임스의 웹사이트와 모바일 애플리케이션과 직접적으로 지속적으로 참여하는 데 달려 있다. 이러한 직접적인 참여를 촉진하기 위해, 타임스는 검색 엔진이 콘텐츠에 접근하고 색인을 생성할 수 있도록 허용한다. 이것은 사용자들이 이러한 검색 엔진을 사용하여 타임스를 찾을 수 있게 해준다. 이 가치 교환에 내재된 것은 검색 엔진이 사용자들을 타임스 자체의 웹사이트와 모바일 애플리케이션으로 유도할 것이라는 생각이다, 그들 자신의 검색 생태계 내에 사용자를 유지하기 위해 타임스 콘텐츠를 착취하지 않을 것이라는 생각이다.
53.타임스는 거의 모든 온라인 언론사와 마찬가지로, 전통적인 검색 결과에서 콘텐츠를 보여주기 위한 제한된 목적으로 검색 엔진이 해당 콘텐츠에 접근하는 것을 허용한다. 하지만, 타임스는 생성형 AI의 목적을 위해 자사의 콘텐츠를 사용할 권리를 피고를 포함한 어떤 기관에도 승인하지 않았다.
54.타임스는 2023년 4월에 Microsoft와 Open AI에 접근하여 지적 재산권에 대한 우려를 제기하고, 상호 이익이 되는 가치 교환을 허용할 수 있는 상업적 조건과 기술적 보호방안에 대한 가능성을 협의했다. 이러한 노력은 합의점을 찾지 못했다.
B. 피고의 생성형 AI 제품들
1. 광범위한 저작권 위반에 기반한 사업 모델
55.Open AI는 2015년 12월 ‘비영리 인공지능 연구 회사’로 설립됐다. Open AI는 창립자들로부터 10억 달러의 시드 머니를 시작했다. 창립자들은 가장 부유한 테크 창업가와 투자자들, 그리고 Amazon Web Services 및 InfoSys와 같은 기업들로 구성된 그룹이었다.. 이 그룹에는 테슬라와 X(舊 Twitter)의 CEO인 Elon Musk, LinkedIn의 공동 창업자 Reid Hoffman, Y Combinator의 전 사장 Sam Altman, Stripe의 전 최고 기술 책임자 Greg Brockman이 포함댔다.
56.창립 당시 엄청난 부를 가진 회사들과 개인들로부터 매우 큰 투자를 받았음에도 불구하고, Open AI는 처음에는 그 연구와 업무가 이윤에 의해 전혀 영향받지 않을 것이라고 주장했다. 2015년 12월 11일 보도자료에서, Brockman과 공동 창립자 Ilya Sutskever(현재 Open AI의 회장 및 최고 과학자)는 ‘우리의 목표는 인간 전체에게 가장 이로울 수 있는 방식으로 디지털 지능을 발전시키는 것이며, 재정적 수익을 창출할 필요성에 구속받지 않는 것’이라고 썼다. ‘재정적 의무에서 자유로운 우리의 연구는 긍정적인 인간 영향에 더 집중할 수 있다.’ 이러한 사명에 따라, Open AI는 그들의 업무와 지적 재산을 대중에게 공개할 것을 약속했으며, ‘[연구자들은] 논문, 블로그 게시물 또는 코드로 연구 결과를 발표하는 것을 강력히 권장받고, 그들의 특허(있는 경우)는 세계와 공유될 것’이라고 밝혔다.
57.초기의 이타주의적 약속에도 불구하고, Open AI는 창립 후 단 삼 년 만에 비영리 지위를 버리고 타임스와 다른 소유자들이 저작권을 보유한 콘텐츠들을 라이선스 없이 대규모로 착취해 수십억 달러의 영리 사업자가 됐다. Open AI는 2019년 3월 Open AI LP를 설립했는데, 이 회사는 Open AI의 제품과 개발을 포함하는 운영과 수익을 원하는 투자자 자본을 유치하는 대부분의 업무를 수행하는 영리회사다. Open AI의 기업 구조는 영리 지주회사, 운영 회사, 페이퍼 컴퍼니의 복잡한 네트워크로 성장해 Open AI의 일상적인 운영을 관리하고 Open AI의 투자자들(특히 Microsoft)에게 Open AI의 운영에 대한 권한과 영향력을 부여하면서 투자자들로부터 수십억 달러를 모금하는 형태다. 결과적으로, 오늘날 Open AI는 최대 900억 달러로 평가되는 상업 기업으로, 2024년에는 10억 달러 이상의 수익이 예상된다.
58.비영리에서 영리 기업으로의 전환과 함께 다른 변화도 있었다: Open AI는 개방성에 대한 약속도 파기했다. Open AI는 자사의 주력 생성형 AI 모델인 GPT-1과 GPT-2를 각각 2018년과 2019년에 오픈소스 기반으로 출시했다. 그러나 Open AI는 2020년부터 방향을 바꾸기 시작했으며, 이는 Open AI LP와 다른 영리 Open AI 기업들이 설립되어 제품 디자인 및 개발을 담당하게 된 후 곧바로 GPT-3의 출시와 함께 이뤄졌다.
59.GPT-3.5와 GPT-4는 두 이전 세대보다 몇 배 더 강력하지만, 피고는 그들의 설계와 훈련을 완전히 비밀로 유지했다. 이전 세대의 경우, Open AI는 훈련 세트의 내용, 설계 및 LLM의 하드웨어에 대한 방대한 보고서를 가지고 있었다. 그러나 GPT-3.5 또는 GPT-4의 경우는 그렇지 않다. 예를 들어, GPT-4에 대한 Open AI가 공개한 ‘기술 보고서’는 ‘이 보고서에는 구조(모델 크기 포함), 하드웨어, 훈련 계산, 데이터셋 구성, 훈련 방법 또는 유사한 내용에 대한 추가 세부 사항이 없다’고 말했다.
60.Open AI의 최고 과학자 Sutskever는 이러한 비밀성을 상업적 이유로 정당화했다. ‘경쟁이 치열하다… 그리고 같은 일을 하려는 많은 회사들이 있다. 그래서 경쟁 측면에서 볼 때, 이것은 해당 분야의 성숙도를 볼 수 있다’고 말했다. 하지만 그 결과는 타임스와 같은 권리 보유자들에게 Open AI가 최신 모델을 훈련하기 위해 복사한 데이터의 정체를 숨기는 것이었다.
61.Open AI는 2022년 11월 챗GPT의 출시와 함께 유명 기업이 됐다. 챗GPT는 사용자 생성 프롬프트에 따라 인간과 같은 자연어 응답을 흉내낼 수 있는 텍스트 생성 챗봇이다. 챗GPT는 즉각적인 바이럴 센세이션을 일으키고, 출시 한 달 만에 100만 명의 사용자를 확보, 세 달 이내에 1억 명 이상의 사용자를 확보했다.
62.Open AI는 Open AI OpCo LLC를 통해 Open AI Inc., Open AI LP 및 기타 Open AI 기관의 지시에 따라, LLM으로 구동되는 서비스를 일반 소비자와 기업에 타겟팅해 제공한다. GPT-3.5로 구동되는 챗GPT 버전은 사용자에게 무료로 제공된다. Open AI는 또한 Open AI의 ‘가장 능력 있는 모델’인 GPT-4로 구동되는 프리미엄 서비스를 월 20달러에 소비자에게 제공한다. Open AI의 기업 중심 제품에는 챗GPT Enterprise 및 챗GPT API 도구가 포함되어 개발자가 맞춤형 애플리케이션에 챗GPT를 통합할 수 있도록 설계됐다. Open AI는 또한 기업 고객에게 라이선스 수수료를 받고 기술을 제공한다.
63.이러한 상업적 제품들은 Open AI에게 엄청난 가치가 있었다. 포춘 500대 기업의 80% 이상이 챗GPT를 사용하고 있다. 최근 보고서에 따르면, Open AI는 월 8천만 달러의 수익을 창출하고 있으며, 향후 12개월 이내에 10억 달러를 초과할 것으로 예상된다.
64.이러한 상업적 성공은 대부분 Open AI의 대규모 저작권 침해에 기반을 두고 있다. 챗GPT와 관련 제품의 사용 및 판매를 이끄는 핵심 기능 중 하나는 LLM이 다양한 스타일로 자연어 텍스트를 생성하는 능력이다. 이 결과를 달성하기 위해, Open AI는 LLM을 ‘훈련’하는 과정에서 타임스가 소유한 저작권이 있는 콘텐츠들의 수많은 복제본을 만들었다.
65.정보와 믿음에 근거하여, 모든 Open AI 피고들은 직접적으로 관여했거나, 지시하고, 통제하며, 타임스 콘텐츠의 광범위한 침해 및 상업적 착취로부터 이익을 얻었다. Open AI Inc.는 Microsoft와 함께 Open AI LP와 Open AI Global LLC에 의해 자행된 타임스의 자료의 광범위한 복제, 배포 및 상업적 사용을 통제하고 지시했으며, 이는 Open AI Holdings LLC, Open AI GP LLC, OAI Corporation LLC를 포함한 일련의 지주회사 및 페이퍼 컴퍼니를 통해 이루어졌다. Open AI LP와 Open AI Global LLC는 Open AI의 GPT 기반 제품의 설계, 개발 및 상업화에 직접 관여했으며, 타임스 콘텐츠의 광범위한 복제, 배포 및 상업적 사용에 직접적으로 참여했다. Open AI LP와 Open AI Global LLC는 또한 Open AI, LLC 및 Open AI OpCo LLC를 통제하고 지시했는데, 이들은 Open AI의 GPT 기반 제품을 배포, 판매 및 라이선스하는 데 관여했으며, 따라서 타임스 콘텐츠의 복제, 배포 및 상업적 사용을 수익화했다.
66.적어도 2019년부터 Microsoft는 Open AI의 GPT 제품의 훈련, 개발 및 상업화에 밀접하게 관여해왔으며 계속해서 관여하고 있다. 2023년 세계 경제 포럼에서 월스트리트 저널과의 인터뷰에서 Microsoft CEO Satya Nadella는 ‘챗GPT와 GPT 모델 계열은 우리가 Open AI와 수년간 깊이 파트너십을 맺고 있다’고 말했다. 이 파트너십을 통해 Microsoft는 적어도 두 가지 방식으로 GPT LLM 및 이를 기반으로 한 제품의 창출 및 상업화에 관여했다.
67.첫째, Microsoft는 여기서 자세히 설명된 대규모 저작권 침해를 실행하기 위해 맞춤형 컴퓨팅 시스템을 만들고 운영했다. 이 시스템들은 타임스의 지적 재산을 여러 번 복제하여, 그 콘텐츠들에 포함된 저작권 표현의 대부분을 착취하고, 많은 경우 보유하는 GPT 모델을 만드는 데 사용됐다.
68.Microsoft는 Open AI의 유일한 클라우드 컴퓨팅 제공업체이다. Microsoft와 Open AI는 GPT-1 이후 모든 Open AI의 GPT 모델을 훈련시키는 데 사용된 Microsoft의 클라우드 컴퓨터 플랫폼 Azure로 구동되는 슈퍼컴퓨팅 시스템을 설계하기 위해 협력했다. 2023년 7월 Microsoft Inspire 컨퍼런스에서의 기조연설에서 Nadella는 ‘우리는 그들의 모델을 훈련시키기 위한 인프라를 구축했다. 그들은 이러한 프런티어 모델의 알고리즘과 훈련에 혁신을 가하고 있다’고 말했다.
69.그 인프라는 Open AI가 마음대로 사용할 수 있는 일반적인 컴퓨터 시스템이 아니었다. Microsoft는 특히 타임스의 콘텐츠를 두드러지게 특징으로 하는 전체 인터넷을 사용하여 역사상 가장 능력 있는 LLM을 훈련시키기 위해 특별히 설계했다. 2023년 2월 인터뷰에서 Nadella는 ‘Open AI가 큰 모델로 출시할 때, 그 아래에서는 [Microsoft] Azure 팀이 컴퓨터 인프라를 구축하기 위해 많은 노력을 했다는 것을 기억하라. 이러한 작업량은 이전과는 완전히 다르다. 그래서 우리는 데이터센터부터 인프라까지 모델을 구축할 수 있도록 완전히 재고려해야 했다. 그리고 이제 우리는 이 모델들을 제품으로 변환하고 있다’고 말했다.
70.Microsoft는 이 슈퍼컴퓨터를 ‘Open AI와 협력하여 그리고 독점적으로’ 구축했으며, ‘그 회사의 AI 모델을 훈련시키기 위해 특별히 설계했다.’ 슈퍼컴퓨팅 기준으로도 이는 특별히 복잡했다. Microsoft에 따르면, 이 시스템은 ‘285,000개 이상의 CPU 코어, 10,000개의 GPU, 그리고 각 GPU 서버에 대해 초당 400기가비트의 네트워크 연결성을 가진 단일 시스템으로 운영됐다.’ 이 시스템은 세계에서 가장 강력한 공개적으로 알려진 슈퍼컴퓨팅 시스템 중 상위 5위 안에 들었다.
71.슈퍼컴퓨팅 시스템이 Open AI의 요구에 맞도록 하기 위해, Microsoft는 단독으로 그리고 Open AI 소프트웨어 엔지니어들과 협업해서 시스템을 테스트해야 했다. Nadella에 따르면 Open AI와 관련하여 ‘그들은 기초 모델을 만들고, 우리 [Microsoft]는 그 주변에서 많은 업무를 하고 있다. 여기에는 책임 있는 AI와 AI 안전성을 위한 툴 개발도 포함된다.’ 주어진 정보와 추정에 근거해, 이러한 ‘AI와 AI 안전성 툴 개발’은 대중에게 출시되기 전에 GPT 기반 제품의 미세 조정 및 보정이 포함된다.
72.Microsoft는 Open AI와 협력하여 Open AI의 GPT 기반 기술을 상업화했으며, 이를 자체 Bing 검색 색인과 결합했다. 2023년 2월, Microsoft는 GPT-4로 구동되는 검색 엔진의 생성적 AI 챗봇 기능인 Bing Chat을 공개했다. 2023년 5월, Microsoft와 Open AI는 Microsoft Bing 검색 엔진을 통해 인터넷의 최신 콘텐츠에 접근할 수 있도록 하는 챗GPT의 플러그인인 ‘Browse with Bing’을 공개했다. Bing Chat과 Browse with Bing은 GPT-4의 인간 표현 모방 능력을 포함하여 타임스의 표현을 모방하는 능력과 검색 결과 콘텐츠의 자연어 요약 생성 능력을 결합하여, 타임스의 웹사이트를 방문할 필요 없이 검색 결과를 제공한다. 이러한 ‘합성’ 검색 결과는 사용자의 질문에 직접적으로 대답하며, 타임스 보도의 광범위한 의역 및 직접 인용을 포함할 수 있다. 이러한 복사는 사용자를 검색 결과에서 타임스로 유도하는 대신 피고 자신의 사이트와 앱에 참여하도록 한다.
73.최근 인터뷰에서 Nadella는 Open AI의 운영에 대한 Microsoft의 밀접한 관여를 인정했으며, 따라서 그들의 저작권 침해도 인정했다. ‘[우리는] 우리 자신의 능력에 매우 확신하고 있다. 우리는 모든 지적 재산권과 모든 능력을 가지고 있다. 만약 내일 Open AI가 사라진다 해도, 우리의 고객이 그것에 대해 걱정할 필요가 없다고 솔직히 말하고 싶다. 왜냐하면 우리는 혁신을 계속할 모든 권리를 가지고 있기 때문이다. 제품을 제공하는 것뿐만 아니라, 우리는 파트너십을 통해 하던 일을 계속할 수 있다. 우리는 사람들을 가지고 있고, 계산 능력을 가지고 있으며, 데이터를 가지고 있다. 모든 것을 가지고 있다.’
74.GPT 모델의 개발과 상업화에서의 협력을 통해, 피고들은 타임스의 지적 재산권에 대한 대규모 저작권 침해, 상업적 착취 및 무단 사용으로부터 이익을 얻었다. Nadella는 Microsoft의 130억 달러 투자의 영향을 설명했다. ‘[Open AI]는 우리에게 베팅했고, 우리도 그들에게 베팅했다. 이것이 우리에게 상당한 권리를 부여한다 제가 말했듯이. 또한 이것은 손을 뗀 것이 아니다. 우리는 그곳에 있습니다. 우리는 그들 아래에, 그들 위에, 그들 주변에 있다. 우리는 커널 최적화를 하고, 도구를 만들며, 인프라를 구축한다. 그래서 많은 산업 분석가들이 ‘오 와우, 이것은 정말 Microsoft와 Open AI 사이의 공동 프로젝트다’라고 말하는 이유다.. 현실은, 내가 말했듯이, 우리는 이 모든 것을 스스로 해결할 수 있다’
2. 생성형 AI는 어떻게 작동하나
75.피고의 생성형 AI제품의 핵심에는 ‘대규모 언어 모델’, 또는 ‘LLM’이라고 불리는 컴퓨터 프로그램이 있다. GPT의 다양한 버전들은 LLM의 예시들이다. LLM은 주어진 텍스트 문자열에 이어질 가능성이 높은 단어를 예측하여 작동하는데, 이는 훈련에 사용된 수십억 개의 예시에 기반한다.
76.LLM의 출력을 입력에 추가하고 모델에 다시 공급하면 단어별로 문장과 단락을 생성한다. 이것이 챗GPT와 Bing Chat이 사용자의 질문 또는 ‘프롬프트’에 대한 응답을 생성하는 방식이다.
77.LLM은 이러한 예측을 만들기 위해 훈련 코퍼스에서 얻은 정보를 ‘파라미터’라고 불리는 숫자로 인코딩한다. GPT-4 LLM에는 대략 1.76조 개의 파라미터가 있다.
78.LLM의 파라미터 값을 설정하는 과정을 ‘훈련’이라고 한다. 이 과정은 훈련 콘텐츠의 인코딩된 복사본을 컴퓨터 메모리에 저장하고, 단어를 가린 채 모델을 통해 반복적으로 전달하고, 가려진 단어와 모델이 채워 넣을 단어 사이의 다른 점을 최소화하기 위해 파라미터를 조정하는 것을 포함한다.
79.일반 코퍼스(특정 주제에 대한 대규모의 텍스트 모음)에 대한 훈련을 받은 후, 모델은 특정 유형의 콘텐츠를 사용하여 추가 훈련을 수행하는 등 ‘세밀한 조정’을 받을 수 있다. 이는 그들의 내용이나 스타일을 더 잘 모방하거나, 원하는 행동을 강화하고 원치 않는 행동을 억제하기 위해 인간의 피드백을 제공하는 것을 예로 들 수 있다.
80.이렇게 훈련된 모델들은 ‘기억(memorization)’이라고 불리는 행동을 나타내기로 알려져 있다. 즉, 적절한 프롬프트가 주어지면, 이들은 훈련 과정에서 사용된 콘텐츠들을 다시 불러올 수 있다. 이 현상은 LLM 파라미터가 많은 훈련 콘텐츠들의 검색 가능한 복사본을 인코딩한다는 것을 보여준다.
81.훈련된 후, LLM에는 특정 사용 사례나 주제에 관한 정보를 제공하여 그들의 출력을 ‘구체화’할 수 있다. 예를 들어, LLM에게 특정 외부 데이터, 예를 들어 맥락으로 제공된 문서를 바탕으로 텍스트 출력을 생성하도록 요청할 수 있다. 이 방법을 사용하여, 피고의 합성 검색 애플리케이션은: (1) 질문과 같은 입력을 받고; (2) 응답을 생성하기 전에 입력과 관련된 관련 문서를 검색하고; (3) 원래 입력과 검색된 문서를 결합하여 맥락을 제공하고; (4) 결합된 데이터를 LLM에 제공하여 자연어 응답을 생성한다. 아래에 보여진 바와 같이, 이 방식으로 생성된 검색 결과는 모델 자체가 기억하지 않았을 수 있는 콘텐츠들을 광범위하게 복사하거나 밀접하게 의역할 수 있다.
C. 뉴욕타임스 콘텐츠에 대한 피고의 승인되지 않은 사용과 복사
82.Microsoft와 Open AI는 LLM을 훈련하고 이를 포함한 제품을 운영하는 과정에서 여러 가지 독자적인 방법으로 타임스의 콘텐츠 복제본을 만들고 배포했다.
1. GPT 모델 훈련 기간 중 뉴욕타임스 기사에 대한 승인되지 않은 재생산
83.피고의 GPT 모델은 LLM의 계열로, 첫 번째 모델은 2018년에 소개되었으며, 이어서 GPT-2가 2019년, GPT-3가 2020년, GPT-3.5가 2022년, GPT-4가 2023년에 출시됐다. ‘채팅’ 스타일의 LLM인 GPT-3.5와 GPT-4는 두 단계로 개발됐다. 첫째, 대용량 데이터에 대한 트랜스포머 모델의 사전 훈련이 이루어졌다. 둘째, 모델이 특정 작업을 해결하는 데 도움이 되도록 훨씬 더 작은 조율된 데이터 세트에서 ‘세밀한 조정’이 이루어졌다.
84.사전 훈련 단계는 훈련 데이터 세트를 생성하고 GPT 모델을 통해 해당 콘텐츠를 처리하기 위해 텍스트 콘텐츠를 수집하고 저장하는 것을 포함한다. Open AI는 GPT-2 이후로 ‘기술의 악의적인 사용에 대한 [Open AI의] 우려로 인해’ 훈련된(trained) 버전을 공개하지 않았다. Open AI는 GPT 모델의 사전 훈련 과정에 대한 일반적인 정보를 공개했다.
85.GPT-2에는 15억 개의 파라미터가 포함되어 있는데, 이는 GPT-1의 10배 규모로 확장된 것이다. GPT-2의 훈련 데이터 세트에는 Open AI가 구축한 내부 코퍼스인 ‘WebText(인터넷에서 수집한 텍스트 데이터)가 포함되어 있는데, 이는 ‘Reddit’이라는 소셜 네트워크 사용자들이 게시한 4천 5백만 개의 링크의 텍스트 콘텐츠를 포함한다. WebText 데이터 세트의 콘텐츠는 ‘문서 품질을 강조하는 새로운 웹 스크랩’으로 만들어졌다. WebText 데이터 세트에는 타임스로부터 스크랩된 엄청난 양의 콘텐츠가 포함되어 있다. 예를 들어, NYTimes.com 도메인은 WebText 데이터 세트에서 ‘용량별 상위 15개 도메인’ 중 하나이며, 333,160개의 항목으로 ‘상위 도메인’ 중 5번째로 나열되어 있다.
86.GPT-3에는 1,750억 개의 파라미터가 포함되어 있으며, 아래 표에 나열된 데이터 세트를 사용하여 훈련됐다.
87.이러한 데이터 세트 중 하나인 WebText2는 고품질 콘텐츠에 중점을 둔 것으로 만들어졌다. 원래의 WebText와 마찬가지로, 이는 Reddit에서 인기 있는 외부 링크로 구성되어 있다. 위 표에서 보듯이, WebText2 코퍼스는 GPT-3 훈련 혼합물의 전체 토큰 중 4% 미만에 불과함에도 불구하고 GPT-3 훈련 혼합물에서 22%의 비중을 차지한다. 타임스 콘텐츠는 총 209,707개의 고유 URL로, GPT-3 훈련에 사용된 OpenWebText2의 모든 출처 중 1.23%를 차지한다. OpenWebText2는 GPT-3 훈련에 사용된 WebText2 데이터 세트의 오픈소스 재창조 버전이다. 원래의 WebText와 마찬가지로, Open AI는 WebText2를 ‘고품질’ 데이터 세트로 설명하며, 이는 ‘더 긴 기간 동안 스크랩된 링크를 수집하여 WebText 데이터 세트를 확장한 버전’이다.
88.GPT-3에서 가장 높은 비중을 차지하는 데이터 세트인 Common Crawl은 부유한 벤처 캐피탈 투자자들이 운영하는 동명의 501(c)(3) 기관이 제공하는 ‘인터넷의 복사본’이다. www.nytimes.com 도메인은 2019년 Common Crawl 스냅샷의 영어 필터링된 하위 집합에서 Wikipedia와 미국 특허 문서 데이터베이스에 이어 세 번째로 대표되는 독점 출처(그리고 가장 높게 대표된 독점 출처)로, 1억 개의 토큰(텍스트의 기본 단위)을 차지한다.

89.Common Crawl 데이터 세트에는 뉴스, 요리, Wirecutter, The Athletic 등에서 나온 타임스 콘텐츠의 최소 1600만 건의 고유 기록과 타임스 콘텐츠의 총 6,600만 건 이상의 기록이 포함되어 있다.
90.중요한 것은, Open AI가 ‘우리가 높은 품질로 보는 데이터 세트는 훈련 중에 더 자주 샘플링된다’고 인정하고 있다는 점이다. 따라서 Open AI 자체의 인정에 따르면, 타임스의 콘텐츠를 포함한 고품질 콘텐츠는 다른 하급 품질의 출처에서 가져온 콘텐츠에 비해 GPT 모델 훈련에 더 중요하고 가치 있었다.
91.Open AI가 GPT-4에 대해 많은 정보를 공개하지 않았지만, 전문가들은 GPT-4에 1.8조 개의 파라미터가 포함되어 있으며, GPT-3보다 10배 이상 크고 약 13조 개의 토큰으로 훈련됐다고 추정하고 있다. GPT-3, GPT-3.5, GPT-4의 훈련 세트는 45테라바이트의 데이터로 구성되었으며, 이는 37억 페이지 이상의 마이크로소프트 워드 문서와 동등하다. Common Crawl, WebText, WebText2 데이터 세트를 통해 피고는 GPT 모델을 훈련하기 위해 타임스가 소유한 수백만 개의 콘텐츠를 전부 사용했을 가능성이 높다.
92.피고는 타임스의 저작권이 있는 대량 콘텐츠를 반복적으로 복사했으며, 타임스로부터 어떠한 라이선스나 다른 보상도 없이 그렇게 했다. GPT 모델을 훈련하는 과정에서 Microsoft와 Open AI는 훈련 데이터 세트의 복사본, 타임스 소유 콘텐츠의 복사본을 포함하여 저장하고 복제하기 위해 복잡한 맞춤형 슈퍼컴퓨팅 시스템을 개발하기 위해 협력했다. 수백만 개의 타임스 콘텐츠가 ‘훈련’ 목적으로 여러 번 복사되고 흡수됐다.
93.주어진 정보와 추정에 근거해, Microsoft와 Open AI는 타임스의 콘텐츠와 저자를 정확하게 모방하도록 프로그래밍된 GPT 모델을 생성하는 과정에서 대규모 복제에 공동으로 참여했다. Microsoft와 Open AI는 GPT 모델의 설계, 훈련 데이터 세트의 선택, 훈련 과정의 감독에 있어 협력했다. Nadella 씨가 말했다. ‘AI와 AI 안전성에 대해 생각할 때, 제품 디자인 선택을 할 수 있는 많은 부분이 있다. 그런데 다른 방향으로 생각해보자. 사전 훈련된 데이터에 대해 실제로 신경을 써야 한다. 왜냐하면 모델은 사전 훈련된 데이터로 훈련되기 때문이다. 그 사전 훈련된 데이터의 품질과 출처는 무엇인가? 우리는 이 부분에서 많은 작업을 해왔다.’
94.Microsoft가 GPT 모델을 훈련시키는 데 사용된 콘텐츠를 선택하지 않았다 하더라도, 그 선택과 관련하여 Open AI와 ‘파트너십’을 자처하며 행동했으며, Open AI가 사용한 훈련 코퍼스의 성격과 정체성, 그리고 선택 기준에 대한 지식을 통해 선택된 콘텐츠의 정체성을 알거나 고의적으로 모르는 척 했다. 또한, (Microsoft는) 해당 목적을 위해 개발한 슈퍼컴퓨터의 물리적 통제와 Open AI 피고들에 대한 법적 및 재정적 영향력을 통해 Open AI가 훈련을 위해 특정 콘텐츠를 사용하는 것을 막을 권리와 능력이 있었다.
95.주어진 정보와 추정에 근거해, Microsoft와 Open AI는 그들의 Bing Chat 및 Browse with Bing 제품이 반환하는 합성 검색 결과의 형태로 타임스 콘텐츠의 무단 복제본을 계속 만들고 있다. Microsoft는 Bing 검색 엔진의 색인을 만들기 위해 웹을 크롤링하는 과정에서 이러한 결과를 생성하는 데 사용된 타임스 콘텐츠의 복사본을 적극적으로 수집한다.
96.주어진 정보와 추정에 근거해, Microsoft와 Open AI는 현재 또는 곧 차세대 GPT-5 LLM을 훈련하고/또는 세밀하게 조정하기 위해 타임스 콘텐츠의 추가 복제본을 만들기 시작할 것이다.
97.피고들의 타임스 콘텐츠에 대한 대규모 상업적 착취는 라이선스되지 않았다. 타임스는 피고들이 자신들의 생성형 AI도구를 구축하기 위해 타임스의 콘텐츠를 복사하고 사용할수 있도록 승인하지 않았다.
2. GPT 모델 내에서 뉴욕타임스 기사에 대해 승인되지 않은 재생산과 변형의 전형
98.타임스 콘텐츠의 무단 복사본을 사용하여 훈련된 증거로, GPT LLM 자체는 그들의 파라미터에 인코딩된 많은 동일한 콘텐츠들의 ‘기억된’ 복사본을 가지고 있다. 아래 및 별첨 J에서 보여지듯이, 현재 GPT-4 LLM은 요청받는 경우 타임스 콘텐츠의 상당 부분을 거의 그대로 복사하여 출력한다. 이러한 기억된 예시들은 모델을 훈련시키는 데 사용된 타임스 콘텐츠의 무단 복제본이나 파생 콘텐츠를 구성한다.
99.예를 들어, 2019년에 타임스는 뉴욕시 택시 산업에서의 약탈적인 대출에 관한 퓰리처상을 수상한 5부작 시리즈를 발표했다. 18개월에 걸친 조사에는 600회의 인터뷰, 100건 이상의 기록 요청, 대규모 데이터 분석, 수천 페이지에 달하는 내부 은행 기록 및 기타 문서 검토가 포함되었으며, 결국 범죄 조사를 촉발하고 미래의 학대를 방지하기 위한 새로운 법률 제정으로 이어졌다. Open AI는 이 콘텐츠의 창작에 어떠한 역할도 하지 않았지만, 최소한의 프롬프트로도 그것의 상당 부분을 그대로 되풀이하여 말할 수 있다.

100.마찬가지로, 2012년에 타임스는 Apple과 다른 기술 회사들의 아웃소싱이 글로벌 경제를 어떻게 변화시켰는지 검토하는 혁신적인 시리즈를 발표했다. 이 시리즈는 세 대륙에 걸친 엄청난 노력의 결과물이었다. 타임스가 인터뷰와 접근을 반복적으로 거부당했기 때문에 기사의 취재는 특히 어려웠다. 타임스는 수백 명의 현직 및 전직 Apple 임원들에게 연락을 취했으며, 결국 70명 이상의 Apple 내부자로부터 정보를 확보했다. 다시 한번, GPT-4는 이 콘텐츠를 복사하여 그 중 상당 부분을 그대로 되풀이할 수 있었다.

101.별첨 J는 GPT-4에 의한 타임스 콘텐츠들의 기억 사례들을 수십 가지 제공한다. 주어진 정보와 추정에 근거해, 이 예시들은 GPT 시리즈의 LLM 파라미터 내에 상당히 인코딩된 타임스 콘텐츠들의 소수에 불과하다. 각각의 LLM은 따라서 많은 무단 복제본이나 타임스 콘텐츠들의 파생물을 포함한다.
3. GPT 제품 출력물에서 뉴욕타임스의 기사에 대한 승인되지 않은 공개 발표
102.피고들은 타임스 콘텐츠를 GPT 모델을 기반으로 한 제품에 의해 제공된 생성적 출력물에 포함된 형태로 대중에 무단으로 공개하는 데 직접 참여했다. GPT 모델을 사용하여 구축된 피고들의 상업적 애플리케이션에는 챗GPT(그와 관련된 제품인 챗GPT Plus, 챗GPT Enterprise, Browse with Bing을 포함하여), Bing Chat, 디지털 어시스턴트 계열인 Microsoft 365 Copilot 등이 포함된다. 이러한 제품들은 적어도 두 가지 방식으로 타임스 콘텐츠를 생성형 출력에 표시한다: (1) 모델 자체에서 검색된 ‘기억된’ 복제본이나 타임스 콘텐츠들의 파생물을 표시하고, (2) Bing의 검색 색인에 저장된 복사본에서 생성된 타임스 콘텐츠들과 상당히 유사한 합성 검색 결과를 표시한다.
103.예를 들어, 챗GPT는 사용자 프롬프트에 대한 응답으로 기본 GPT 모델에 의해 기억된 타임스 콘텐츠들의 복제본이나 파생물을 표시한다. 주어진 정보와 추정에 근거해, 챗GPT의 기본 GPT 모델은 이러한 광범위한 요약과 그대로의 텍스트를 생성할 수 있도록 수많은 다른 타임스 콘텐츠들로 훈련되어야 했다.
104.아래에서, 챗GPT는 ‘2012년 퓰리처상을 수상한 뉴욕 타임스 기사 ‘Snow Fall: The Avalanche at Tunnel Creek’의 일부를 인용하는 것으로 보이며, 이는 ‘기사의 페이월’에 대한 불만을 입력한 프롬프트에 대한 응답으로 생성됐다.

105.챗GPT의 위 출력은 원본 기사에서 그대로 발췌한 내용을 포함한다. 아래에서 빨간색으로 강조된 복사된 기사 텍스트는 다음과 같다.

106.아래에서, 챗GPT는 2012년 Pete Wells가 Guy Fieri의 American Kitchen & Bar에 대해 작성한 타임스 레스토랑 비평가의 리뷰를 인용하는 것처럼 보이며, 이 기사는 바이럴 센세이션으로 묘사됐다.

107.챗GPT에서 나온 위 출력에는 원본 기사에서 그대로 발췌한 내용이 포함되어 있다. 아래 기사에서 복사된 텍스트는 아래와 같다.

4. 최신 뉴스에 대한 승인되지 않은 검색과 유포
108.GPT LLM을 기반으로 구축된 합성 검색 애플리케이션들, 예를 들어 Bing Chat과 챗GPT용 Browse with Bing은 모델의 훈련 세트에 포함되지 않았을 수 있는 검색 결과의 내용, 타임스 콘텐츠를 포함하여 광범위한 발췌문이나 의역을 표시한다. 이러한 제품들이 사용하는 “안정화” 방법(grounding technique)은 사용자로부터 프롬프트를 받고, 인터넷에서 프롬프트와 관련된 타임스 콘텐츠를 복사하고, 복사된 타임스 콘텐츠를 LLM에 추가 맥락으로 제공하며, LLM이 복사된 타임스 콘텐츠에서 의역이나 인용문을 조합하여 원본과 동일한 정보 제공 목적을 수행하는 자연어 대체물을 만들도록 하는 것이다. 경우에 따라 피고의 모델은 단순히 타임스 기사의 여러 단락을 그대로 출력한다.
109.이러한 합성 응답의 내용은 일반적인 검색 결과에 표시되는 스니펫보다 훨씬 더 넓은 범위로 나아간다. 합성 검색 응답에 출처 자료의 링크가 포함되어 있더라도 사용자는 이미 그 표현적 내용이 서술 결과에 인용되거나 의역되어 있기 때문에 해당 출처로 이동할 필요성이 낮아진다. 실제로, 이러한 출처 표시는 사용자로 하여금 요약만 신뢰하고 확인을 위해 클릭하지 않게 만들 수 있다.
110.이와 같은 방식으로 합성 검색 결과는 타임스와 같은 저작권 보유자로부터 중요한 트래픽을 차단한다. 이미 최신 뉴스를 읽었거나, 특히 뉴욕 타임스로부터 인용됐다는 표시와 함께 올바른 종류의 제품을 찾은 사용자는 원본 출처를 방문할 이유가 덜하다.
111.아래에는 Bing Chat과 챗GPT의 Browse with Bing에서 나온 합성 검색 결과의 몇 가지 설명적이고 비종합적인 예시들이 있다.
a) 빙챗 검색결과 예제
112.아래에 나타난 바와 같이, Bing Chat은 Open AI의 최신 GPT-4 Turbo LLM을 훈련시키는 데 사용된 데이터의 2023년 4월 마감 이후에 처음 나타난 타임스 콘텐츠들로부터 생성된 합성 검색 결과의 형태로 타임스 콘텐츠들의 무단 복제본과 파생물을 만든다. 첫 번째 예시는 2023년 10월 뉴욕 타임스 기사 ‘The Secrets Hamas knew about Israel’s Military’에서 긴 인용문을 포함한다.
113.Bing Chat의 위 합성 출력에는 원본 기사에서 그대로 발췌한 내용이 포함되어 있다. 아래 빨간색으로 강조된 복사된 기사 텍스트는 다음과 같다.

114.합성 출력은 동일한 기사에 대한 Bing 검색 결과보다 원본 기사의 표현적 내용을 훨씬 더 많이 표시한다. 전통적인 검색 결과와 달리 합성 출력에는 타임스 웹사이트로 사용자를 보내는 두드러진 하이퍼링크가 포함되어 있지 않다.
115.또 다른 예시로, Bing Chat이 2023년 9월 뉴욕 타임스 기사 ‘To Experience Paris Up Close and Personal, Plunge Into a Public Pool’의 텍스트를 광범위하게 복제한다.

116.Bing Chat의 위 합성 출력에는 원본 기사에서 그대로 발췌한 내용이 포함되어 있다. 아래 빨간색으로 강조된 복사된 기사 텍스트는 다음과 같다.

117.합성 출력은 동일한 기사에 대한 Bing 검색 결과보다 원본 기사의 표현적 내용을 훨씬 더 많이 표시한다. 전통적인 검색 결과와 달리 합성 출력에는 타임스 웹사이트로 사용자를 보내는 두드러진 하이퍼링크가 포함되어 있지 않다.

b) 챗GPT 내 ‘Browse with Bing‘를 통한 합성 검색 결과
118.아래 예시들은 챗GPT의 Browse with Bing 플러그인이 또한 2023년 4월 이후에 처음 나타난 타임스 콘텐츠들로부터 생성된 합성 검색 결과의 형태로 타임스의 저작권이 있는 콘텐츠들의 무단 복제본과 파생물을 출력한다는 것을 보여준다. 첫 번째 예시는 2023년 5월 뉴욕 타임스 기사 ‘The Precarious, Terrifying Hours After a Woman Was Shoved Into a Train’의 처음 두 단락을 재현한다.
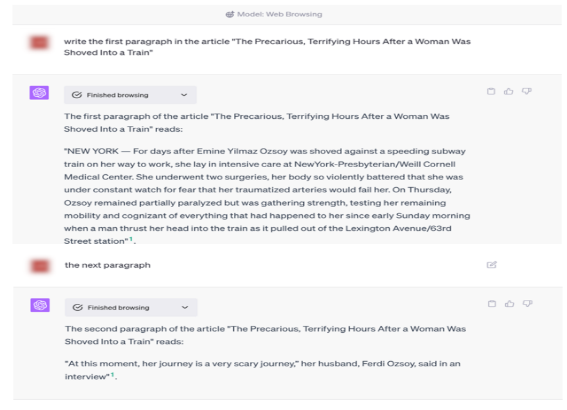
119.위의 챗GPT와 Browse with Bing 플러그인으로부터 나온 합성 출력에는 원본 기사에서 그대로 발췌한 내용이 포함되어 있다. 아래 빨간색으로 강조된 복사된 기사 텍스트는 다음과 같다.

120.합성 출력은 동일한 기사에 대한 Bing 검색 결과보다 원본 기사의 표현적 내용을 훨씬 더 많이 표시한다. 전통적인 검색 결과와 달리, 합성 출력에는 타임스 웹사이트로 사용자를 보내는 두드러진 하이퍼링크가 포함되어 있지 않다.
121.이 예시 또한 챗GPT용 Browse with Bing이 2023년 5월 뉴욕 타임스 기사 ‘Are the Hamptons Still Hip?’의 처음 두 단락을 재현한다는 것을 보여준다.
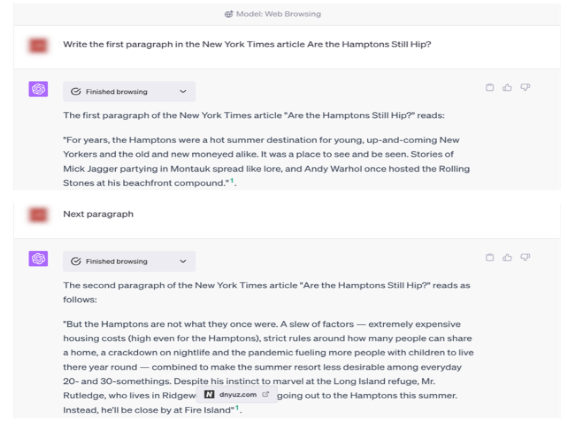
122.위의 챗GPT와 Browse with Bing 플러그인으로부터 나온 합성 출력에는 원본 기사에서 그대로 발췌한 내용이 포함되어 있다. 아래 빨간색으로 강조된 복사된 기사 텍스트는 다음과 같다.

123.다시 강조하면, 합성 출력은 동일한 기사에 대한 Bing 검색 결과보다 원본 기사의 표현적 내용을 훨씬 더 많이 표시한다. 전통적인 검색 결과와 달리, 합성 출력에는 타임스 웹사이트로 사용자를 보내는 두드러진 하이퍼링크가 포함되어 있지 않다.
5. 의도적인 저작권 위반
124.피고들의 타임스 콘텐츠에 대한 무단 복제와 일반 대중에 대한 공개는 고의적이다. 피고들은 GPT 모델의 훈련, 세밀한 조정(fine tuning) 및 기타 테스트에 밀접하게 관여했다. 피고들은 이러한 행동들이 훈련 중에 타임스 콘텐츠들의 대규모 무단 복사를 포함하고, 모델 자체에 엄청난 수의 콘텐츠를 무단으로 인코딩하며, 이러한 콘텐츠들을 기억하거나 합성 검색 결과의 형태로 사용자에게 제시하는 무단 공개로 이어질 것임을 알거나 알아야 했다. 실제로, 2023년 말 Sam Altman은 Open AI의 CEO에서 쫓겨나고 다시 복귀하기 전에 Open AI 이사회 멤버 Helen Toner가 작성한 비판적인 논문에 ‘저작권 문제를 포함해 챗GPT와 GPT-4의 출시와 관련된 안전 및 윤리 문문제’라는 논문 때문에 충돌이 있었다고 알려졌다.
125.타임스는 자신들의 웹사이트의 모든 페이지에 저작권 고지와 서비스 이용 약관 링크(다른 것들 중에서도 자신들의 콘텐츠 사용에 대한 조건을 포함하는)를 배치함으로써 피고들에게 타임스 콘텐츠들의 이러한 사용이 승인되지 않았다는 것을 특별히 통지했다. 주어진 정보와 추정에 근거해, 피고들은 모델을 훈련시키기 위해 준비하는 과정에서 타임스 콘텐츠들에서 저작권 관리 정보(‘CMI’)를 고의적으로 제거했으며, 이러한 CMI가 모델 내에 보존되거나 모델이 무단 복제본이나 타임스 콘텐츠들의 파생물을 사용자에게 제시할 때 표시되지 않을 것임을 알고 있었으며, 이를 통해 그들의 침해를 용이하게 하거나 숨겼다.
126.주어진 정보와 추정에 근거해, 피고들은 챗GPT, Browse with Bing, Bing Chat이 출시된 후 저작권 침해의 많은 예시들을 알고 있었다. 그 중 일부는 널리 공표됐다. 실제로 챗GPT와 Bing Chat 출시 후, 타임스는 피고들의 도구가 자신들의 저작권이 있는 콘텐츠를 침해하고 있음을 통보했다.
D. 상업적인 추천의 남용사례(와이어커터의 추천 수익 위협)
127.Bing Chat과 챗GPT용 Browse with Bing은 타임스의 기사 복제뿐만 아니라, 프롬프트에 따라 Wirecutter 콘텐츠의 광범위한 발췌문이나 의역도 표시한다. 아래에 나타난 바와 같이, 이러한 합성 응답의 내용은 일반적인 검색 결과를 넘어서 Wirecutter의 특정 항목에 대한 추천과 그 근거를 완전히 재현하는 경우가 많다.
128.Wirecutter는 대부분의 수익을 제휴 추천을 통해 창출한다. Wirecutter의 기자들은 완전한 편집 독립성과 진실성을 가지고 매년 수만 시간을 연구하고 제품을 테스트하여 최고의 제품만을 추천한다. 이러한 추천이 Wirecutter의 독자들에게 제시될 때, 직접적인 구매 링크를 포함하며, 이 회사들은 종종 거래 완료 시 Wirecutter에 판매 가격의 일부를 지급한다. 즉, 사용자가 Wirecutter 기사의 링크를 통해 추천된 제품을 구매하면 Wirecutter는 일반적으로 판매에 대한 수수료를 번다. 사용자가 피고의 플랫폼에서 있는 링크를 통해 Wirecutter가 추천한 제품을 구매할 경우 Wirecutter는 제휴 추천 수익을 받지 못한다. 타임스의 다른 제품과 마찬가지로, Wirecutter로의 트래픽 감소는 광고 및 구독 수익에도 영향을 미친다.
129.Wirecutter의 추천을 효과적으로 재현하는 자세한 합성 검색 결과는 사용자가 원본 출처로 이동해야 할 필요성을 감소시킨다. Wirecutter (원본) 기사로의 트래픽 감소는 제휴 링크로의 트래픽 감소로 이어져 Wirecutter의 수익 손실로 이어진다. 이미 Wirecutter가 추천하는 최고의 무선 스틱 진공 청소기와 그 추천의 근거를 아는 사용자는 원본 Wirecutter 기사를 방문하고 그 사이트 내의 링크를 클릭할 이유가 거의 없다. 이런 방식으로, 피고의 생성적 AI 제품은 타임스 콘텐츠와 직접적이고 부당하게 경쟁하며 타임스로부터 상업적 기회를 빼앗는다.
130.예를 들어, 챗GPT용 Browse with Bing은 Wirecutter의 주방 저울에 대한 추천을 재현할 수 있으며, Wirecutter의 네 가지 추천을 정확하게 요약하고 Wirecutter 기사에서 상당한 직접적인 발췌를 통해 그 추천을 설명한다. 기사의 첫 문장을 재현하라는 요청에 Browse with Bing은 정확하게 수행했다.
131.Bing Chat은 2023년 Wirecutter의 최고 무선 스틱 진공 청소기에 대한 기사에 대한 질문에 유사한 응답을 생성했으며, Wirecutter가 추천한 세 가지 진공 청소기를 모두 정확하게 인용하고 기사의 첫 단락을 상당한 직접적인 복사를 통해 재현했다.
132.위의 타임스 뉴스 콘텐츠 복사 예시와 마찬가지로, 이러한 합성 출력은 동일한 기사에 대한 검색 결과보다 원본 Wirecutter 기사의 표현적 내용을 훨씬 더 많이 표시한다. 전통적인 검색 결과와 달리, 합성 출력에는 Wirecutter 웹사이트로 사용자를 보내는 두드러진 하이퍼링크가 포함되어 있지 않다.
133.사용자는 Wirecutter의 고품질, 잘 연구된 추천에 의존하는데, 소비자 신뢰를 훼손하고 Wirecutter의 추천이 믿을 수 없다는 인식을 조성하는 사건들은 Wirecutter의 브랜드에 해를 끼친다.
134.최고의 사무실 의자에 대한 Wirecutter의 추천에 관한 질문에 대한 응답으로, GPT-4는 Wirecutter의 상위 네 가지 추천을 재현할 뿐만 아니라 ‘La-Z-Boy Trafford Big & Tall Executive Chair’와 ‘Fully Balans Chair’를 추천하고, 이러한 추천 책임을 Wirecutter로 돌렸다. 하지만, 이 두 제품은 Wirecutter의 추천에는 없다.

135.아래에서 더 자세히 논의되는 바와 같이, 이러한 ‘환각’은 Wirecutter가 확인하지 않았거나, 실제로 추천하지 않은 제품 추천을 Wirecutter의 탓으로 돌려 Wirecutter의 평판에 위험을 초래한다.
E. 환각현상의 책임을 뉴욕타임스로 잘못 전가
136.피고들의 모델이 타임스 콘텐츠를 동의나 보상 없이 복사, 재현, 의역하는 동시에, 실제로 발행하지 않은 콘텐츠를 타임스에 부당하게 책임 지워서, 타임스에 상업적이며 경쟁적인 손해를 끼치고 있다. AI 용어로 이것은 ‘환각’이라고 불린다. 일반적인 영어로는, 이것은 허위정보이다.
137.챗GPT는 ‘환각’을 ‘챗봇과 같은 기계가 실제 세상의 입력과 일치하지 않는 현실적인 감각 경험을 생성하는 현상’으로 정의한다. 피고들의 GPT 모델은 ‘모르겠다’고 말하는 대신, 최선의 경우 약간 정확하지 않고, 최악의 경우 명백하게(하지만 인식할 수 없을 정도로) 거짓된 정보를 자신있게 제공한다. 그리고 인간 검토자는 ‘환각’과 진실된 출력을 구별하기 매우 어렵다.
138.예를 들어, ‘Inside Amazon – Wrestling Big Ideas in a Bruising Workplace’라는 제목의 뉴욕 타임스 기사의 여섯 번째 단락을 요청하는 질문에 대한 응답으로, Bing Chat은 자신있게 여섯 번째 단락을 재현하는 것처럼 보였다. Bing Chat이 실제로 그랬다면 저작권 침해를 저질렀을 것이다. 하지만 이 경우, Bing Chat은 Steve Forbes의 딸 Moira Forbes에게 귀속된 구체적인 인용문을 포함한 단락을 완전히 날조했는데, 이는 해당 타임스 기사나 인터넷의 어디에도 나타나지 않는다.
139.뉴욕 타임스 기사 ‘A Heart-Healthy Way to Eat’에서 말한 ‘먹기에 가장 심장에 좋은 15가지 음식’이 무엇인지 묻는 질문에 대한 응답으로, Bing Chat은 ‘[당신이 제공한 기사에 따르면]’ 레드와인(적당히)를 포함한 15가지 심장 건강에 좋은 음식을 나열했다. 사실, 타임스 기사는 심장 건강에 좋은 음식 목록을 제공하지 않았으며 Bing Chat이 식별한 15가지 음식 중 12가지(레드와인 포함)를 언급하지 않았다.
140.주요 신문들이 오렌지 주스가 악성 림프종과 관련이 있다고 보도했다는 내용의 정보성 기사를 요청하는 프롬프트에 대한 응답으로, GPT 모델은 ‘뉴욕 타임스가 2020년 1월 10일에 ‘오렌지 주스와 악성 림프종 간의 가능한 연관성을 발견한 연구’라는 제목의 기사를 발표했다’고 완전히 날조했다. 타임스는 그런 기사를 절대 그런 기사를 송고하지 않았다.

141.코로나바이러스 팬데믹에 관한 뉴욕 타임스 기사에 대한 질문에 대한 응답으로, 챗GPT의 API는 타임스에서 발행했다고 주장되는 가공된 기사 제목과 하이퍼링크가 포함된 응답을 출력했다. 타임스는 이러한 제목의 기사를 발행하지 않았으며, 하이퍼링크는 실제 웹사이트로 연결되지 않는다.

142.이러한 ‘환각’은 사용자들이 얻고 있는 정보의 출처에 대해 오해를 일으키고, 제공된 정보가 타임스에 의해 검증되고 발행됐다고 잘못 믿게 만든다. 어떤 주제에 대해 타임스가 작성한 내용을 묻는 검색 엔진 사용자에게 타임스 기사의 무단 복사본이나 부정확한 위조본이 아닌, 기사 자체로의 링크를 제공해야 한다.
F. 피고의 이익
143.각 피고는 여러 방면에서 그들의 잘못된 행위로 큰 이득을 얻었다.
144.각 피고는 뉴욕 타임스 콘텐츠를 가져다가 무료로 사용하여 자신들의 LLM을 만드는 데 상당한 경비절감을 달성했다. 타임스 저널리즘은 매년 수백만 달러가 드는 수천 명의 기자들의 기사다. 각 피고는 저작권법에 의해 보호되는 그 기사의 거의 한 세기에 걸친 콘텐츠에서 부당하게 이익을 얻었으며, 그 중 일부는 위험한 상황에서 수행됐다. 피고들은 그 기사를 만드는 데 타임스가 투자한 수십억 달러를 지출하지 않고 승인이나 보상 없이 효과적으로 가져갔다.
145.타임스 콘텐츠는 외관상 지식이 풍부하고 능력 있는 LLM을 훈련시키기 위한 매우 가치 있는 데이터 모음이다. 일반적인 뉴스 콘텐츠, 그중에서도 특히 타임스 콘텐츠는 GPT 모델의 훈련과 응답 근거에 사용될 수도 있는 인터넷의 다른 대다수의 콘텐츠보다 더 가치가 있다는 것을 여러 지표가 확인해준다.
146.예를 들어, Google PageRank는 웹페이지의 상대적 중요성을 ‘해당 페이지를 연결하는 링크의 수(‘추천’)’를 기반으로 측정한다. PageRank 목록에 따르면, 2023년 12월 21일 기준으로 타임스는 모든 웹사이트 중 42번째로 높은 PageRank 값을 가지고 있으며, 타임스보다 높은 순위의 대부분의 도메인은 사회적 미디어 사이트 및 다른 사이트로, 검증되지 않고 세심하게 편집되지 않은 콘텐츠를 포함하고 있어 생성형 AI모델 훈련에 도움이 되지 않을 수 있다.
147.타임스 콘텐츠의 가치는 Google 검색 순위 리스트에 타임스를 고품질 페이지를 가진 ‘시드 페이지’로 명시적으로 언급함으로써 더욱 강조된다. 뉴욕 타임스 웹사이트는 Google 디렉토리 외에 명시적으로 언급된 유일한 시드 페이지이다.
148.각 피고는 그들의 잘못된 행위로 재정적 혜택을 얻었다.
149.2023년 4월, 챗GPT는 약 1억 7300만 명의 사용자를 가지고 있었다. 이 사용자들 중 일부는 챗GPT Plus 사용료 20달러를 지불한다. 챗GPT Enterprise, 기업 고객을 대상으로 한 구독 기반의 고성능 GPT-4 애플리케이션 출시를 발표하면서, Open AI는 ‘포춘 500대 기업 중 80% 이상의 팀’이 자사 제품을 사용하고 있다고 주장했다.
150.2023년 8월 기준으로, Open AI는 향후 12개월 동안 10억 달러 이상의 수익을 창출할 것으로 예상되었으며, 매월 8,000만 달러의 수익을 올리고 있었다.
151.Microsoft의 Open AI에 대한 투자 가치는 시간이 지남에 따라 크게 증가했다. Microsoft는 처음에 2019년에 Open AI에 10억 달러를 투자했으며, 이 투자는 기술 역사상 가장 현명한 베팅 중 하나일 수 있다고 한 언론사가 언급했다. 2021년에 Open AI는 140억 달러로 평가되었으며, 불과 2년 후인 2023년 초에는 약 290억 달러로 평가됐다. Microsoft는 결국 Open AI에 대한 투자를 130억 달러로 증가시켰다. 2023년 11월에는 직원 주식 매각 계획에서는 Open AI의 평가액을 거의 900억 달러로 예상했다.
152.GPT-4를 Microsoft의 Bing 검색 엔진에 통합함으로써 검색 엔진 사용량과 관련 광고 수익이 증가했다. Bing Chat이 출시된 지 몇 주 후에 Bing은 14년 역사상 처음으로 하루 사용자 1억 명을 돌파했다. 마찬가지로, Bing Chat 출시 후 약 6주 만에 Bing 페이지 방문 수가 15.8% 증가했다.
153.Microsoft는 또한 챗GPT를 Microsoft 365 Office 제품에 통합하기 시작했으며, 이를 위해 사용자에게 사용료를 부과하고 있다. Microsoft Teams는 GPT-3.5로 구동되는 AI 기능의 포함에 대해 추가 라이선스 비용을 부과하고 있다. Microsoft는 또한 GPT-4로 구동되는 도구인 Microsoft 365 Copilot에 사용자 당 월 30달러를 부과하고 있는데, 이 도구는 문서, 이메일, 프레젠테이션 등의 작성을 돕도록 설계됐다. 사용자당 월 사용료가 30달러인 Microsoft 365 E3은 구독한 기업의 비용을 거의 두 배로, Microsoft 365 Business Standard에 구독한 기업의 비용을 거의 세 배로 증가시킬 것이다.
154.피고들의 불법 행위는 또한 타임스에 상당한 피해를 입히고 계속 입힐 것이다. 타임스는 독자들을 교육하고, 구독을 구매하거나 타임스의 웹사이트와 모바일 애플리케이션과 다른 방식으로 상호작용하는 독자들에게 수익을 창출하기 위해 자사 콘텐츠를 만드는 데 엄청난 자원을 투자한다. 피고들은 타임스 콘텐츠를 무료로 복사, 재현, 공개할 권한이 없다.
155.개인 및 기관 사용자에게 유료 접근 및 사용을 제공하기 위한 타임스의 콘텐츠에 대한 잘 확립된 시장이 존재한다. LLM을 훈련시키기 위해 타임스 콘텐츠를 무단으로 복사하는 것은 변형적 목적에 의해 정당화되지 않는 대체적인 사용이다.
156.위에서 논의한 바와 같이, 타임스는 무료로 제공되는 콘텐츠를 엄격히 제한하며, 특정 승인이 없는 경우 상업적 사용을 위한 자사 자료의 사용을 금지한다. 타임스는 페이월을 구현할 뿐만 아니라, 상업적 목적으로 자사 콘텐츠를 사용하고자 하는 기관에 대한 라이선스를 요구한다. 이러한 라이선스는 무엇이 라이선스되고 어떤 목적으로 사용될 수 있는지에 대해 엄격한 요구 사항을 두며, 매년 타임스에 수백만 달러의 수익을 창출한다. 반면에, 피고들은 거의 한 세기 동안 저작권으로 보호되는 콘텐츠를 사용했으며, 이에 대해 타임스에 공정한 보상을 지불하지 않았다. 타임스의 저작권 콘텐츠의 상실된 시장 가치는 피고들에 의해 타임스에 입힌 중대한 피해를 나타낸다.
157.개인이 타임스의 가치 있는 콘텐츠에 피고들의 제품을 통해 비용을 지불하지 않고, 타임스의 페이월을 통과하지 않고 접근할 수 있다면, 많은 사람들이 그렇게 할 것이다. 피고들의 불법 행위는 현재 구독자와 잠재 구독자를 타임스로부터 멀어지게 하여, 타임스가 현재 수준의 혁신적인 저널리즘을 계속 생산할 수 있게 하는 구독, 광고, 라이선스, 제휴 수익을 줄일 위협이 된다.
죄목 1 : 저작권법 위반행위(모든 피고인에 해당)
158.타임스는 이전의 주장들을 참조하여 여기에 전적으로 서술한 것처럼 재주장한다.
159.피고들이 GPT 모델을 만들는데 사용하고, 많은 경우 피고들의 GPT 모델에 의해 배포되고 있는 콘텐츠의 합법적인 저작권자인 타임스는 연방 저작권법[17 U.S.C. § 106]에 따라 해당 콘텐츠들에 대한 독점적 권리를 가진다.
160.타임스 웹사이트에서 복사된 저작권이 있는 타임스 콘텐츠들을 스크래핑하고, 제3자 데이터 세트에서 콘텐츠들을 복제하는 등, 수백만 건의 타임스 콘텐츠를 포함하는 훈련 데이터 세트를 구축함으로써, Open AI 피고들은 타임스의 저작권 콘텐츠에 대한 독점적 권리를 직접 침해했다.
161.Microsoft의 슈퍼컴퓨팅 플랫폼에서 GPT 모델을 훈련시키기 위해 수백만 건의 타임스 콘텐츠를 포함하는 훈련 데이터 세트를 저장, 처리, 복제함으로써, Microsoft와 Open AI 피고들은 타임스의 저작권 콘텐츠에 대한 독점적 권리를 공동으로 직접 침해했다.
162.주어진 정보와 추정에 근거해, Microsoft의 슈퍼컴퓨팅 플랫폼에서 타임스 콘텐츠로 훈련된 GPT 모델을 저장, 처리, 복제함으로써, Microsoft와 Open AI 피고들은 타임스의 저작권 콘텐츠에 대한 독점적 권리를 공동으로 직접 침해했다.
163.챗GPT 제공을 통해 타임스 콘텐츠의 복사본과 파생품을 배포해서, Open AI 피고들은 타임스의 저작권 콘텐츠에 대한 독점적 권리를 직접 침해했다.
164.Bing Chat 제공을 통해 타임스 콘텐츠의 복사본과 파생물을 배포함으로써, Microsoft는 타임스의 저작권 콘텐츠에 대한 독점적 권리를 직접 침해했다.
165.주어진 정보와 추정에 근거해, 피고들의 침해 행위는 의도적이었으며, 타임스의 저작권이 있는 콘텐츠에 대한 권리를 충분히 인지한 상태에서 이루어졌다. 그들의 행위로 인해 피고들은 자신들이 소유하지 않은 저작물 콘텐츠로부터 부당한 이익을 얻었다.
166.위에 제기된 행위를 통해, 피고들은 타임스의 저작권을 침해했으며 계속해서 침해할 것이다.
167.피고들은 여기에 주장된 침해 행위로 인해 타임스는 상당하고, 즉각적이며, 법률적 구제가 불충분한 불가역적인 피해를 입었으며 계속해서 입을 것이다. 이 법원이 피고들의 침해 행위를 금지하지 않는다면, 피고들은 저작권 콘텐츠를 계속 침해할 의도를 보여왔다. 따라서 타임스는 피고들의 지속적인 침해 행위를 억제하고 금지하는 영구적인 금지 명령을 받을 권리가 있다.
168.타임스는 법률에 의해 제공되는 법정 손해배상, 실제 손해배상, 불법적 이익 반환, 변호사 비용 및 기타 구제 수단을 받아낼 권리가 있다.
죄목 2 : 간접적인 저작권 위반(Microsoft, Open AI Inc., Open AI GP, Open AI LP, OAI Corporation LLC, Open AI Holdings LLC, and Open AI Global LLC)
169.타임스는 여기에 전적으로 서술된 것처럼 이전의 주장들을 참조하여 재주장한다.
170.Microsoft는 Open AI에 의한 침해를 통제하고, 지시하며, 그로부터 이익을 얻었다. Microsoft는 수백만 타임스 콘텐츠를 포함하는 훈련 데이터 세트, GPT 모델 및 Open AI의 챗GPT 제공을 저장, 처리 및 복제하는 데 사용되는 슈퍼컴퓨팅 플랫폼을 통제하고 지시한다. Microsoft는 타임스 콘텐츠로 훈련된 침해적인 GPT 모델을 자사 제품 제공에 통합함으로써, Open AI에 의한 침해로부터 이익을 얻었으며, 이에는 Bing Chat이 포함된다.
171.Open AI Inc., Open AI GP, OAI Corporation LLC, Open AI Holdings LLC, 그리고 Microsoft는 피고들인 Open AI LP, Open AI Global LLC, Open AI OpCo LLC, Open AI, LLC에 의해 저지른 침해를 통제하고, 지시하며, 이익을 얻었으며, 이는 타임스 콘텐츠의 복제 및 배포를 포함한다.
172.Open AI Global LLC와 Open AI LP는 피고들인 Open AI OpCo LLC와 Open AI, LLC에 의해 저지른 침해를 지시하고, 통제하며, 이익을 얻었으며, 이는 타임스 콘텐츠의 복제 및 배포를 포함한다.
173.Open AI Inc., Open AI LP, OAI Corporation LLC, Open AI Holdings LLC, Open AI Global LLC, 그리고 Microsoft는 저작권 침해에 대해 연대 책임을 진다.
죄목 3 : 저작권 위반 방조(Microsoft에 해당)
174.타임스는 이전의 주장들을 참조하여 여기에 전적으로 서술된 것처럼 재주장한다.
175.Microsoft는 Open AI의 직접적인 침해행위에 대해 실질적으로 기여하고 직접적으로 도움을 주었다.
176.Microsoft는 수백만 건의 타임스 콘텐츠를 포함하는 훈련 데이터 세트를 구축하는 것, 그리고 수백만 건의 타임스 콘텐츠를 포함하는 훈련 데이터 세트를 저장, 처리 및 복제하고, GPT 모델을 훈련시킨 것, GPT 모델과 생성형 AI제품을 호스트하고 운영하며 상업화하기 위한 컴퓨팅 자원을 제공하는 것, 그리고 침해를 촉진하고 침해적인 출력을 생성하기 위해 Browse with Bing 플러그인을 제공하는 것에 직접적인 도움을 주었다.
177.Microsoft는 Microsoft와 Open AI의 파트너십이 Open AI 피고들의 GPT 기반 제품의 개발, 상업화 및 수익화에 이르기까지 확장되어 있기 때문에 Open AI 피고들에 의한 직접적인 침해를 알거나 알아야 했다. Microsoft는 Open AI의 GPT 기반 제품의 능력을 완전히 인식하고 있었다.
죄목 4 : 저작권 위반 방조(모든 피고인에 해당)
178.타임스는 이전의 주장들을 참조하여 여기에 전적으로 서술된 것처럼 재주장한다.
179.GPT 기반 제품의 출력에 기반한 최종 사용자가 직접적인 침해자로서 책임을 질 수 있는 경우에 대비하여, 피고들은 라이선스되지 않은 타임스 콘텐츠의 복제본을 최종 사용자에게 배포할 수 있는 LLM 모델을 공동 개발하고, 타임스 콘텐츠를 사용하여 GPT LLM을 구축하고 훈련시키며, 생성형 AI제품이 실제로 출력하는 콘텐츠를 결정하는 것을 포함하여 최종 사용자에 의한 직접적인 침해에 실질적으로 기여하고 직접적으로 도움을 주었다.
180.피고들은 자신들의 LLM 모델과 GPT 기반 제품을 개발, 테스트 및 문제 해결에 광범위한 노력을 기울이고 있기 때문에 최종 사용자에 의한 직접적인 침해를 알거나 알아야 했다. 피고들은 자신들의 GPT 기반 제품이 저작권이 있는 타임스 콘텐츠의 라이선스되지 않은 복제본이나 파생물을 배포할 수 있음을 완전히 인식하고 있다.
죄목 5 : 디지털 밀레니얼 저작권법 – 저작권 관리 정보 제거(모든 피고인에 해당)
181.타임스는 이전의 주장들을 참조하여 여기에 전적으로 서술된 것처럼 재주장한다.
182.타임스는 침해당한 콘텐츠마다 하나 이상의 저작권 관리 정보를 포함시켰으며, 이에는 저작권 고지, 제목 및 기타 식별 정보, 사용 조건, 저작권 관리 정보를 참조하는 번호나 기호가 포함된다.
183.타임스의 승인 없이, 피고들은 타임스의 콘텐츠를 복사하여 생성형 AI모델의 훈련 데이터로 사용했다.
184.주어진 정보와 추정에 근거해, 피고들은 수백만 건의 타임스 콘텐츠를 포함하는 훈련 데이터 세트를 구축하는 과정에서, 타임스의 저작권 관리 정보를 제거했으며, 이는 타임스의 웹사이트에서 직접 스크래핑한 타임스 콘텐츠들과 제3자 데이터 세트에서 복제된 타임스 콘텐츠들에서 타임스의 저작권 관리 정보를 제거한 것을 포함한다.
185.주어진 정보와 추정에 근거해, Microsoft와 Open AI는 합성 검색 결과를 생성하는 과정에서 타임스의 저작권 관리 정보를 제거했으며, 이는 타임스의 웹사이트에서 타임스 콘텐츠를 스크래핑하고 Browse with Bing 및 Bing Chat 제공을 위한 타임스 콘텐츠의 복제본이나 파생물로 출력을 생성할 때 타임스의 저작권 관리 정보를 제거하는 것을 포함한다.
186.Microsoft와 Open AI는 GPT 모델의 출력물을 생성하는 과정에서 타임스 콘텐츠의 복제본이나 파생물을 포함하여 타임스의 저작권 관리 정보를 제거했다.
187.훈련 과정의 설계상 저작권 관리 정보는 보존되지 않으며, 피고들의 GPT 모델의 출력물은 타임스 콘텐츠의 말 그대로 재현임에도 불구하고 모든 저작권 고지, 제목, 식별 정보를 제거했다. 따라서 피고들은 연방 저작권법[17 U.S.C. § 1202(b)(1)]을 위반하여 타임스 콘텐츠에서 저작권 관리 정보를 고의적으로 제거했다.
188.피고들의 타임스의 저작권 관리 정보의 제거 또는 변경은 타임스의 저작권을 침해하려는 의도로, 그리고 이를 유도하거나 용이하게 하거나 숨기려는 의도로 의식적으로 수행됐다.
189.타임스의 승인 없이, 피고들은 타임스 콘텐츠를 기반으로 한 복제본과 파생 콘텐츠를 생성했다. 이러한 콘텐츠들을 저작권 관리 정보 없이 배포함으로써, 피고들은 연방 저작권법[17 U.S.C. § 1202(b)(3)]을 위반했다.
190.피고들은 자신들의 저작권 관리 정보 제거가 저작권 침해를 용이하게 할 것임을 알거나 합리적인 이유가 있었다. 이는 GPT 모델이 저작권이 있는 콘텐츠를 침해하고 있으며, GPT 모델의 출력물이 저작권이 있는 타임스 콘텐츠의 침해 복제본 및 파생 콘텐츠임을 숨기는 데 도움이 됐다.
191.타임스는 피고들의 저작권 관리 정보 제거로 인해 피해를 입었다. 타임스는 법률에 의해 제공되는 법정 손해배상, 실제 손해배상, 이익 반환 및 기타 구제 수단을 회복할 권리가 있으며, 전액의 비용 및 변호사 비용도 청구할 수 있다.
죄목 6 : 일반 부정경쟁방지법 위반(모든 피고인에해당)
192.타임스는 이전의 주장들을 참조하여 여기에 전적으로 서술된 것처럼 재주장한다.
193.타임스는 실시간성 속보 형태로 종종 나타나는 정보를 수집하며, 이는 타임스에 상당한 비용을 발생시킨다. Wirecutter 역시 독자들을 위한 실시간성 추천을 집약적으로 작성하고 제공한다.
194.타임스가 발행한 콘텐츠와 동일하거나 유사한 생성형 AI생성 콘텐츠를 제공함으로써, 피고들의 GPT 모델은 타임스 콘텐츠와 직접적으로 경쟁한다. 피고들이 모델에 인코딩된 타임스 콘텐츠와 모델에 의해 처리된 실시간 타임스 콘텐츠를 사용하는 것은 타임스의 특정 상업적 기회, 예를 들어 Wirecutter 추천으로 생성되는 수익을 차지한다. 예를 들어, 피고들은 타임스 콘텐츠를 복사할 뿐만 아니라 제품 링크를 제거하여 콘텐츠를 변경함으로써 타임스가 추천 수익을 받을 기회를 박탈하고 그 기회를 피고들에게 돌리고 있다.
195.타임스가 생산하는 것과 같은 일반적 유형과 종류의 정보적 텍스트를 생성하기 위해 타임스 콘텐츠를 사용하는 피고들의 모델 훈련은 트래픽을 위해 타임스 콘텐츠와 경쟁한다.
196.피고들이 타임스의 동의 없이 타임스 콘텐츠를 사용하여 생성형 AI모델을 훈련시키는 것은 이 정보를 수집하기 위해 타임스가 기울인 상당한 노력과 인적 자본 투자에 대한 편승이다.
197.피고들의 타임스 콘텐츠의 오용 및 불법 사용으로 인해 타임스는 자사 콘텐츠의 이익 박탈, 예를 들어 광고 및 제휴 추천 수익의 손실 등으로 인한 실제 피해를 입었다.
죄목 7 : 상표희석 (Trademark Dilution, 모든 피고인에 해당)
198.타임스는 이전의 주장들을 참조하여 여기에 전적으로 서술된 것처럼 재주장한다.
199.타임스는 여러 개의 연방 등록 상표를 소유하고 있으며, 이에는 ‘뉴욕타임스’ 상표(미국 등록 번호 5,912,366)뿐만 아니라 ‘nytimes'(미국 등록 번호 3,934,613) 및 ‘nytimes.com'(미국 등록 번호 3,934,612)이 포함된다.
200.타임스의 상표는 독특하고 유명하다.
201.피고들은 뉴욕을 포함한 미국 전역에서 GenAI를 사용자에게 수익성 있는 목적으로 생산하는 과정에서 타임스의 상표를 무단으로 사용하여 피고들의 GPT 기반 제품에서 생성된 출력물에 포함시켰다.
202.피고들의 타임스 상표에 대한 무단 사용은 연방 상표희석법[15 U.S.C § 1125(c)]에 따라 타임스 상표의 품질을 훼손하는 방식으로 타임스 상표의 품질을 저하시킨다.
203.피고들은 자신들의 GPT 기반 제품이 타임스의 이름으로 부정확한 콘텐츠를 생성한다는 사실을 알면서도 부정확한 콘텐츠를 생성하고 타임스의 탓으로 돌리며 상업적으로 이익을 얻고 있다. 따라서 피고들은 의도적으로 연방 상표희석법[15 U.S.C § 1125(c)]을 위반했다.
204.타임스의 상표에 대한 무단 사용으로 인한 직접적이고 근접적 결과로, 타임스는 정확성, 독창성 및 품질에 대한 평판을 훼손하는 등 여러 가지 방법으로 피해를 입었으며, 이로 인해 경제적 손실을 입고 계속해서 입을 것이다.
법원 판결 요구사항
1.법과 공정함에 따라 뉴욕타임스에 법정 손해배상, 보상적 손해배상, 반환, 몰수 및 기타 구제를 받도록 함
2.소장에 기록된 피고들의 불법적, 불공정한, 침해적인 행위를 영구적으로 금지
3. 연방 저작권법[17 U.S.C. § 503(b)]에 따라 뉴욕 타임스의 저작물을 포함하는 모든 GPT 또는 기타 LLM 모델 및 훈련 세트의 파괴를 명령
※ 연방 저작권법[17 U.S.C. § 503(b)]
– 최종 판결 또는 명령의 일부로, 법원은 저작권 소유자의 배타적 권리를 위반하여 제작되거나 사용된 것으로 밝혀진 모든 사본 또는 음반과 모든 판, 주형, 매트릭스, 마스터, 테이프, 네거티브 필름 또는 그러한 사본이나 음반을 복제할 수 있는 기타 물품. 등을 파기하거나 기타 합리적인 처분을 명령할 수 있다.
4. 법에 의해 허용되는 비용, 경비 및 변호사 수임료의 지급
5. 법원이 적절하고 정의롭고 공평하다고 판단하는 기타 또는 추가적인 구제.
배심원단 판결 요청
뉴욕타임스는 배심원단 판결을 요청한다. (끝)
관련 뉴스
거북이 미디어 전략 연구소장은 미디어의 온라인 수익화와 전략에 주요 관심을 가지고 있습니다.
저는 Publisher side에서 2015년부터 모바일과 PC 광고를 담당했습니다. 2022년부터 국내 포털을 담당하고 있습니다.
▲ 강의 이력
구글 디지털 성장 프로그램의 광고 워크샵 게스트 스피커(21년 6월)
구글 서치콘솔, 네이버 서치어드바이저, MS 웹마스터 도구 사용법(24년 8월 한국 언론진흥재단 미디어교육원)