네이버 홈피드는 개인화 추천의 새 지평을 열며 2023년 8월 네이버 모바일 메인에 도입된 혁신적인 서비스입니다. 사용자의 검색 및 클릭 데이터를 기반으로 맞춤형 콘텐츠를 제공하며, 도입 이후 활성 사용자(DAU)가 600% 증가, 클릭 수가 800% 상승하는 놀라운 성과를 기록했습니다.
이 글에서는 2024년 11월 네이버 통합 컨퍼런스에 발표된 자료를 기반으로 네이버 홈피드의 핵심 AI 기술과 추천 최적화 전략을 정리합니다. DCN Ranker, MDE Ranker, Calibration, TransAct와 같은 첨단 모델을 중심으로 사용자의 행동 패턴과 선호도에 맞춘 추천 시스템의 원리와 도입 효과를 탐구합니다.
네이버 홈피드 서비스 개요
홈피드란 무엇인가?
홈피드는 네이버가 2023년 8월 11일 네이버 모바일 메인에 도입한 개인화 추천 피드로 검색홈 하단에 제공됩니다. 구글 디스커버와 비슷한 콘텐츠 추천 서비스입니다. 구글 디스커버는 뉴스를 포함하지만 네이버 홈피드는 뉴스를 제외합니다.
홈피드 도입 후 성과
홈피드 도입 이후 네이버 활성 사용자(DAU)는 600% 증가, 클릭 수는 800% 증가라는 성과를 기록했습니다.
홈피드에 추천되는 콘텐츠 구조
콘텐츠 출처
- 네이버 블로그
- 네이버 카페
- 네이버 TV
- 네이버 포스트
- 네이버 클립(숏폼)
- 네이버 인플루언서
- 프리미엄콘텐츠
사용자 활동 기반 추천
- 노출/클릭 이력 : 사용자 클릭 및 검색 이력에서 선호 키워드 및 주제군 추출
- 구독 정보 : 구독 채널과 카페 게시판
- 검색 이력 : 검색어 연관 문서
- 주제 선호도
- 피드백 카드 이력
위의 네이버 콘텐츠와 사용자 활동 이력을 기반으로 해서 콘텐츠가 추천됩니다.
- 검색 이력 -> 검색 쿼리 연관 문서
- 소비 이력 -> EASE, tow-tower 모델
- 인기도 : 선호 카테고리 인기 문서, 동일 성별/연령대

홈피드를 위한 추천 프로세스
핵심모델 : 리트리버(Retriever)
네이버 홈피드는 사용자 행동에 즉각 반응하는 리트리버를 구축해 사용자가 방금 검색한 것과 연관된 문서를 보여주거나 사용자가 방금 홈피드에서 클릭한 문서와 연관된 문서를 보여줍니다
| ※ 리트리버(Retriever)란? – “리트리버(retriever)”는 해당 문맥에서 “정보 검색 시스템에서 원하는 정보를 찾아주는 역할을 하는 도구 또는 기능”을 의미합니다. 특히 사용자가 입력한 쿼리나 행동을 기반으로 관련 문서를 찾아서 제공하는 시스템 – “사용자의 행동에 즉각 반응하는 리트리버 구축하기”는 사용자의 니즈를 빠르게 이해하고 관련 정보를 실시간으로 제공하는 검색 또는 추천 시스템 개발을 의미 |
AfterSearch Retriever(사용자가 방금 검색한 것과 연관된 문서를 보여줌)
- 사용자가 하루 이내 검색한 이력과 연관된 문서를 추천
- AfterSearch Retriever 도입 후 홈피드 클릭 이력 사용성이 거의 없는 lihgt 사용자군 대상 지표가 상승하는 결과
- Light 사용자군 지표 : Rank1 CTR +5.4%, 전체 클릭 수 +2.1%, 문서 다양성 +34.7%, 스크롤 세션 비율 +1.1%

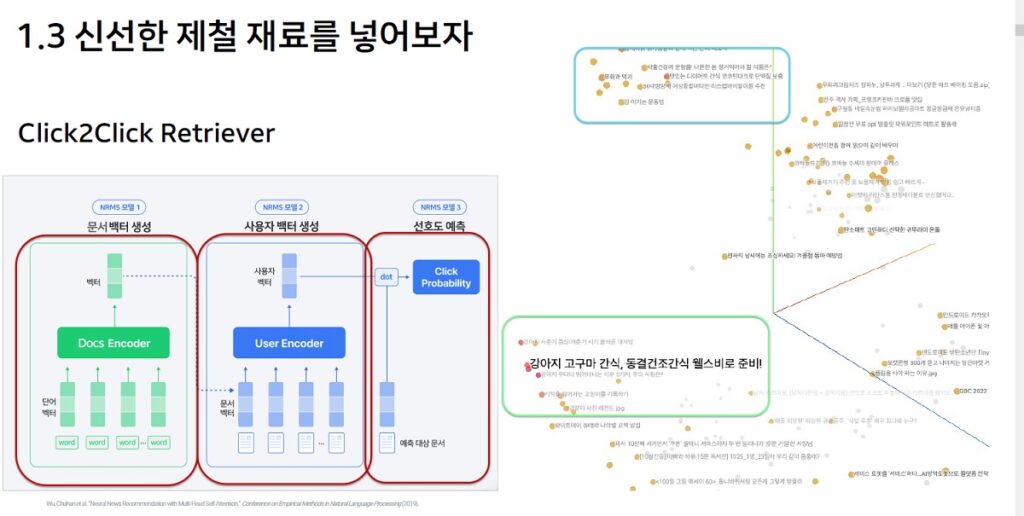
Click2Click Retriever(사용자가 방금 홈피드에서 클릭한 문서와 연관된 문서를 보여줌)
- 사용자가 하루 이내 클릭한 문서 중 최신 이력과 연관된 문서를 추천
- 홈피드 사용성이 적당하고 풍부한 Medium/Heavy 사용자의 대상 지표 상승하는 결과
- Medium/Heavy 사용자 지표 증가 : Rank1 CTR +4.07%/+2.37%, 전체 클릭 수 +1.07%/1.42%, 문서 다양성 +0.9%/+1.53%, 스크롤 세션 비율 +1.32%/0.87%

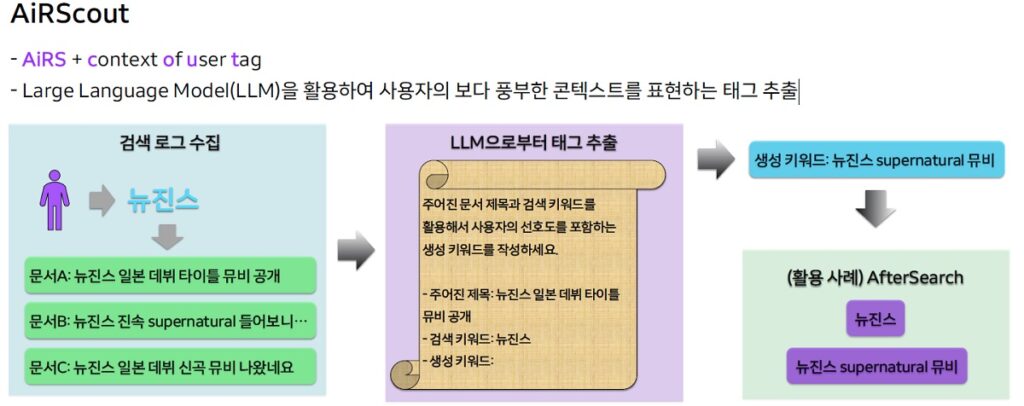
LLM 활용 : AIRScout
- LLM(Large Language Model)을 활용하여 사용자의 보다 풍부한 콘텍스트를 표현하는 태그 추출
- AIRScout: AiRS + context of user tag
| ※ 네이버 AiRS란? – 네이버가 2017년 2월 발표한 자료에 따르면 AiRS(AI Recommender System, 에어스)는 네이버가 자체 연구, 개발한 인공지능 기반 추천 시스템이며 CF(Collaborative Filtering, 협력 필터) 기술과 인공신경망 기술인 RNN(Recurrent Neural Network)에 기반을 뒀음 [출처] 인공지능 기반 추천 시스템 AiRS를 소개합니다 ※ LLM이란? 자연어 처리 분야에서 가장 중요한 기술 중 하나로, 대규모의 텍스트를 학습하여 다양한 언어 작업을 수행할 수 있는 인공지능 모델이다. 거대 언어 모델이라는 이름은 언어 모델의 매개변수가 수십억 개 이상으로 매우 많기 때문에 기존의 모델과 구분하기 위해 부여된 이름이다. [출처] 네이버 지식백과] 거대 언어 모델 [Large Language Models] (두산백과 두피디아, 두산백과) |
LLM을 활용한 주제 분류기

홈피드 추천 랭킹 로직 구성
추천 목표
- 다양한 특징을 가진 콘텐츠를 한 피드 안에서 랭킹
- 유저가 클릭할 확률 뿐 아니라 만족할 확률 또한 예측하여 랭킹
- 정확한 추천 뿐 아니라 다양하게 발견 및 탐색할 수 있도록 추천
- future works : 유저의 시계열 행동 패턴을 반영한 추천
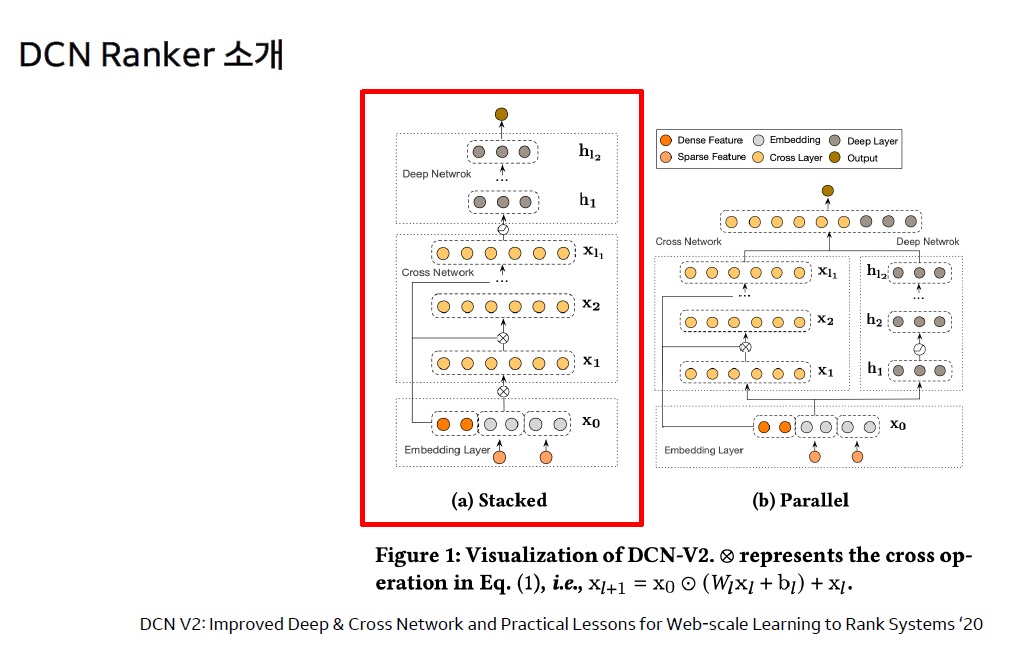
DCN Ranker : 다양한 콘텐츠를 한 피드 안에서 랭킹
- DCN(Deep Cross Network) Ranker
- DCN Ranker의 AB 테스트 결과 기존 Linear Ranker 대비 클릭 지표 크게 상승
- 전체 클릭수 + 9.43%, Rank1 CTR +8.37%, 전체 CTR +8.99%

| ※ DCN(Deep Cross Network)란? – DCN은 이미 널리 알려진 딥러닝 모델로, 네이버는 이를 검색 서비스와 개인화에 성공적으로 응용함 – 네이버가 사용한 DCN은 2021년 Wang et al.이 발표한 논문 “DCN V2: Improved Deep & Cross Network and Practical Lessons for Web-scale L2R Systems”에서 소개한 모델. 이는 기존 DCN 모델의 개선 버전으로, 웹 스케일의 학습 시스템에 적합하도록 설계됨 |
사용자 맞춤형 첫번째 콘텐츠 노출
MDE Ranker : 유저가 클릭할 확률과 만족할 확률을 예측하여 랭킹
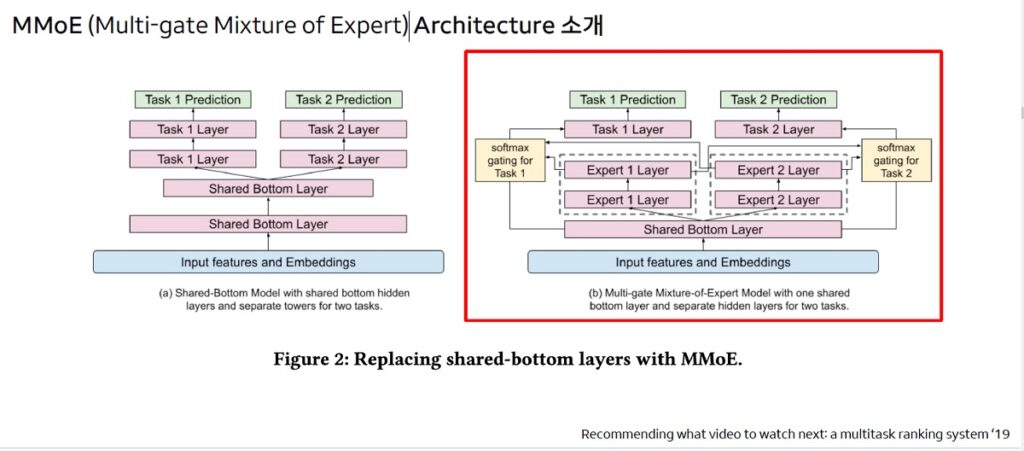
- 만족할 확률 = 체류시간이 길 확률
- MDE(Multi Deep Experts) Ranker는 MMoE (Multi-gate Mixture of Expert) Architecture + DCM
- MDE Ranker의 AB 테스트 결과 DCN Ranker 대비 신규 사용자와 클릭 지표가 크게 상승함
- 신규 사용자 수 +1.85%, 전체 CTR +4.19%, 클릭 사용자 비율 +2.31%, Rank1 CTR +5.70%

| ※ MDE Ranker란 – MDE(Multi Deep Experts) Ranker는 기존의 DCM 모델에 MMoE (Multi-gate Mixture of Expert) Architecture를 결합한 모델로 기존 네이버 스마트블록 개인화 검색에 사용함 – MDE Ranker는 Deep Cross Network(DCN) 모델을 활용하여 피처 간의 복잡한 상호작용을 효과적으로 모델링하고, 이를 통해 검색 결과의 품질을 향상시킴 |
Calibration(조정) : 정확한 추천 + 다양한 발견 및 탐색
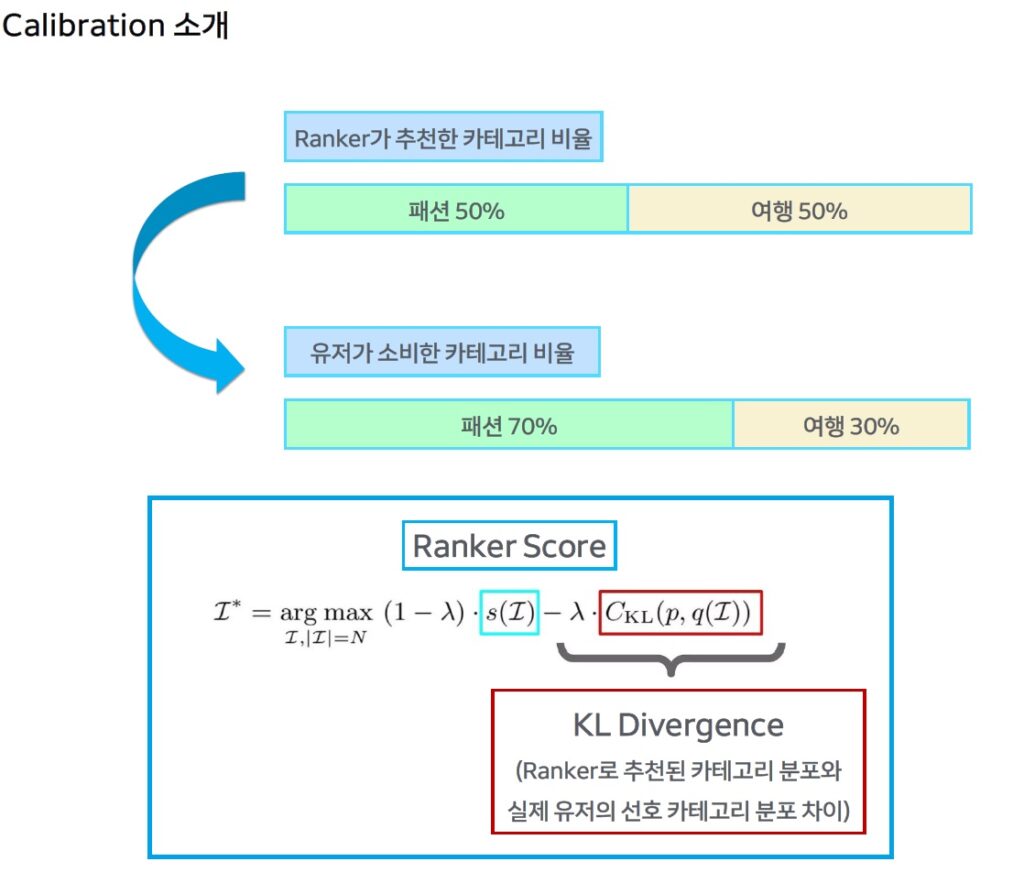
- Calibration은 추천 시스템에서 Ranker가 제안한 콘텐츠 분포와 사용자의 실제 선호 콘텐츠 분포 간의 차이를 조정하는 작업으로 정확한 추천 및 다양한 발견과 탐색을 가능하게 함
- 사용자의 선호와 Ranker가 추천한 카테고리 비율 사이의 차이를 KL Divergence 등의 수치로 측정하고 이를 최소화하여 조정
- AB 테스트 결과 클릭 및 체류 시간 등의 지표 상승 및 정성적 품질 개선
- 전체 CTR +1.11%, 인당 체류시간 +0.46%, 인당 클릭수 +1.53%
| ※ KL Divergence(Kullback-Leibler Divergence)란? – KL Divergence는 두 확률 분포 간의 차이를 측정하는 통계적 개념. 한 분포(사용자 실제 선호 P : 패션 70%, 여행 30%)가 참이라고 가정할 때, 다른 분포(Ranker 추천 분포 Q : 패션 50%, 여행 50%)를 이용해 표현할 때 발생하는 정보 손실(불확실성)을 측정함 – 네이버는 KB Divergence를 통해 Ranker 추천 분포와 사용자의 실제 소비 분포 간의 차이를 측정하여 추천 결과를 조정(Calibration) |
TransAct : future works – 유저의 시계열 행동 패턴을 반영한 추천
- TransAct는 네이버의 검색 및 추천 시스템에서 사용자의 시계 행동 데이터를 효과적으로 활용하여 개인화된 콘텐츠를 제공하는 데 중점을 둔 기술
- TransAct는 Transformer를 활용한 실시간 사용자 행동 모델로 핀터레스트 사례에서 도입된 “Transformer-based Real-time User Action Model for Recommendation”에서 착안함
- 기존의 배치 처리 방식과 달리, TransAct는 실시간으로 업데이트되는 사용자의 최근 검색, 클릭, 구매 행동 등 사용자 행동 데이터를 분석하여 추천 품질을 높임
- 사용자의 실시간 행동 데이터를 반영하여 개인화된 추천 품질을 극대화.사용자가 이전에 보인 관심사뿐 아니라, 현재 관심 있는 콘텐츠를 더 잘 반영
사용자 맞춤형 첫번째 콘텐츠 노출
사용자 유형에 따른 첫번째 콘텐츠 알고리즘을 맞춤형으로
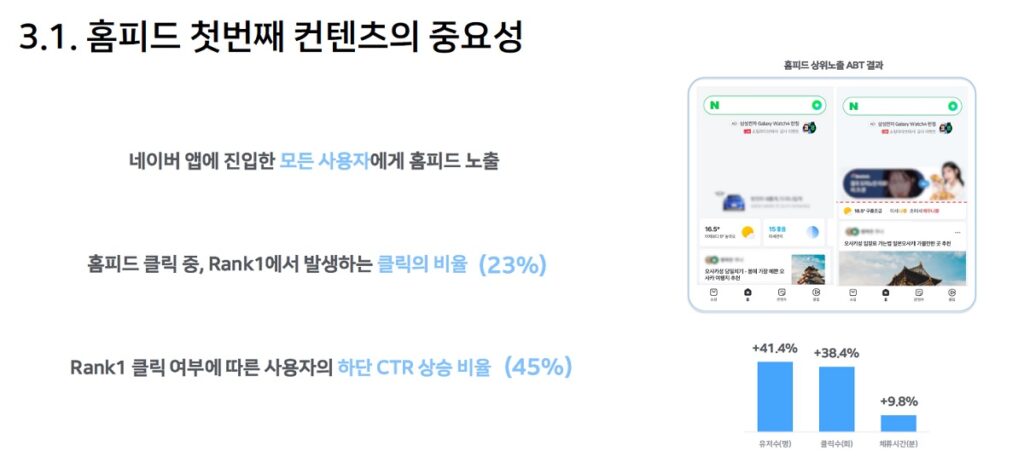
- 첫번째 콘텐츠는 서비스의 첫 이미지로 매우 중요
- 어떤 콘텐츠를 Rank1에 제공해야 사용자의 이목을 끌 수 있을지 고민
- 네이버 앱에 진입한 모든 사용자에 홈피드를 노출했더니 홈피드 클릭 중 Rank1에서 발생하는 클릭 비율이 23%, Rank1 클릭 여부에 따른 사용자의 하단 CTR 상승 비율은 45%였음
- 사용자 맞춤형 Rank1 콘텐츠를 아래와 같이 선정함
- Light 사용자는 컨텍스트가 적어서 홈피드에 대한 인식이 낮음 -> 현재 관심사인 검색 결과로 Rank1 추천
- Medium 사용자는 컨텍스트가 충분해서 홈피드에 대한 긍정적 인식이 있고 선호도 파악이 가능함 -> 최근 클릭한 콘텐츠와 유사한 Rank1을 추천
- Heavy 사용자 -> 기존 컨텍스트를 유지하고 다양한 콘텐츠를 접하도록 추천

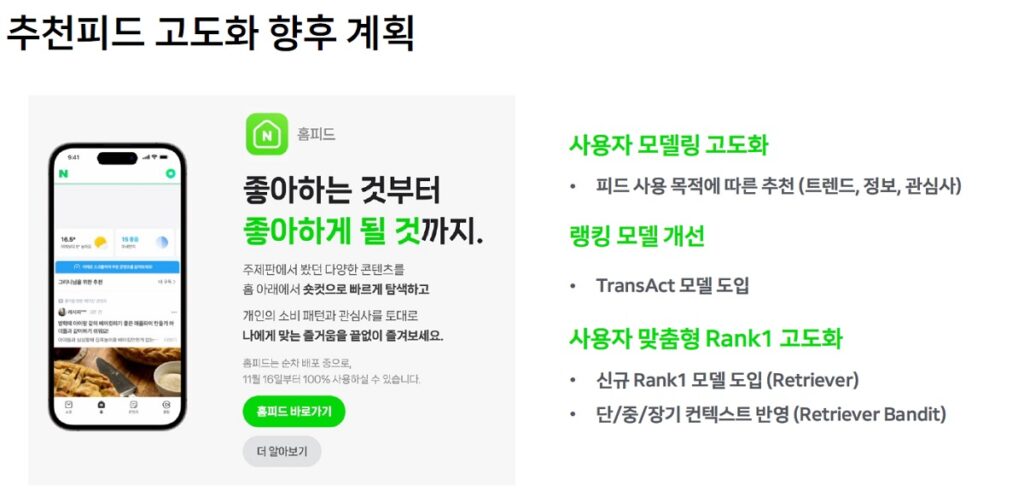
추천피드 고도화 계획
- 네이버는 사용자가 좋아하게 될 것까지 추천할 수 있도록 사용자 모델링을 고도화, 랭킹 모델 개선, 사용자 맞춤형 Rank1 고도화를 진행할 계획임
(끝)
관련 포스팅
거북이 미디어 전략 연구소장은 미디어의 온라인 수익화와 전략에 주요 관심을 가지고 있습니다.
저는 Publisher side에서 2015년부터 모바일과 PC 광고를 담당했습니다. 2022년부터 국내 포털을 담당하고 있습니다.
▲ 강의 이력
구글 디지털 성장 프로그램의 광고 워크샵 게스트 스피커(21년 6월)
구글 서치콘솔, 네이버 서치어드바이저, MS 웹마스터 도구 사용법(24년 8월 한국 언론진흥재단 미디어교육원)