네이버 검색이 대규모 언어 모델(LLM, Large Language Model)을 도입해 검색 품질을 대폭 개선한 사례를 공개했습니다. LLM을 활용해 최신성을 반영하고 사용자의 검색 의도를 정교하게 파악하여, 더 정확하고 만족도 높은 검색 결과를 제공하게 되었습니다.
이 글에서는 네이버 검색이 LLM을 검색에 적용하며 비용 효율성을 극대화한 과정과, 이를 통해 얻은 구체적인 성과와 기술적 접근법을 살펴봅니다.
성과 정리 : 네이버 검색의 RRA-T 모델 도입 성과
네이버는 RRA-T 모델을 도입한 후 A/B 테스트에서 다음 성과를 확인했습니다.
- 상위 5개 문서 클릭률(CTR): 12.32% 상승
- 전체 클릭 수: 10.3% 증가
- 검색 품질 향상: 사용자 피드백을 기반으로 설계한 Prompt 덕분에 검색 결과 신뢰도가 높아짐
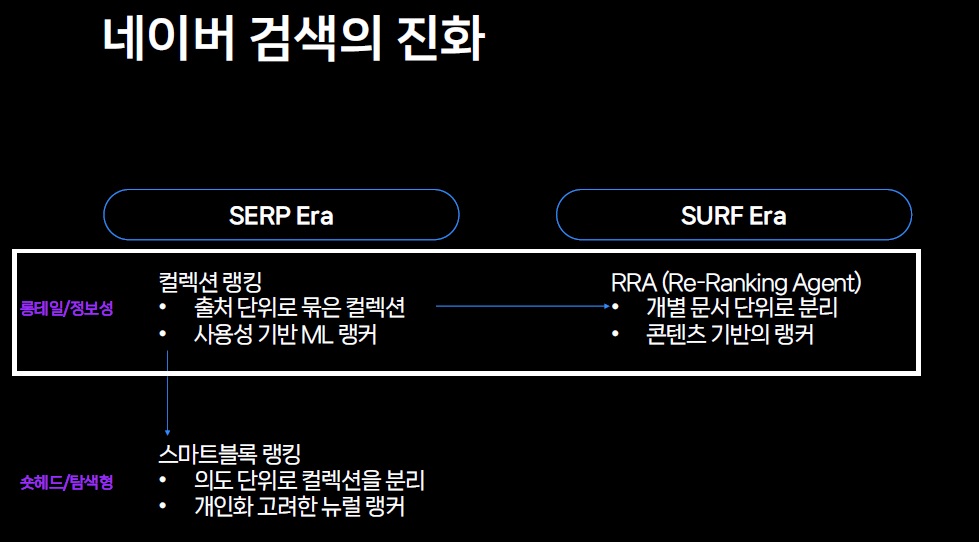
검색 결과 페이지 중심에서 사용자 탐색 시대로 전환
네이버 검색은 검색 결과 페이지(SERP Era)에서 사용자 탐색 중심 시대(SURF Era)로 전환했습니다.
검색 서비스에서의 LLM 사용
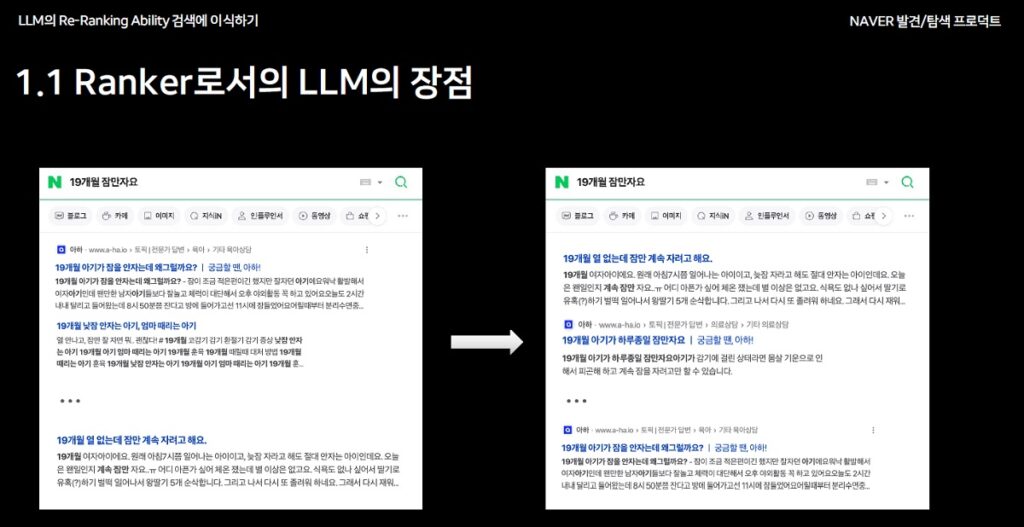
LLM(Large Language Model)은 대규모 데이터를 학습하여 문맥과 연관성을 깊이 이해할 수 있는 언어 모델입니다. 검색 엔진에서 LLM은 Ranker 역할을 수행하며, 사용자가 원하는 정보를 신속하고 정확하게 제공하지만 한계점도 있습니다
Ranker(검색 순위 결정 도구)로서의 LLM의 장점
- 복잡한 맥락 이해: 사용자의 검색어를 분석해 적합한 결과 제공
- 롱테일 질의 처리: 명확한 답이 없는 질의에도 높은 정확도로 결과 제공
- 유연성: 다양한 검색 요구 사항에 맞춰 문서를 효율적으로 정렬.
검색 서비스에서 LLM 사용의 한계
하지만 LLM을 실시간 검색 서비스에 전면 도입하기에는 다음과 같은 한계가 존재합니다.
- 실시간 랭킹 처리를 하기에는 느린 속도
- 높은 운영 비용과 어려운 관리 문제
네이버는 이러한 문제를 극복하기 위해 LLM의 효율성을 극대화하면서도 비용을 절감하는 방법을 모색했습니다. 아래는 네이버가 롱테일 질의를 해결하기 위해 LLM을 활용해 Re-Ranking을 개선한 방법입니다. Re-ranking이란 사용자가 입력한 검색어에 대한 검색결과를 다시 정렬해 더 적합한 순서로 보여주는 기술입니다.
LLM을 이용해 롱테일 질문에 대한 Re-Ranking 개선
롱테일 키워드 개선을 위한 내부 검토
’19개월 잠만 자요’ 같은 롱테일 키워드 개선을 위해 네이버 검색 개발자들은 아래와 같은 내용들을 시도합니다.
| 여러 시도들 | 문제점 |
| 유저 피드백 데이터셋 | Long-tail 질의 관련 유의미한 피드백이 없거나 매우 적다 |
| Bi-encoder 형식 모델 구조 | 의도가 명확하지 않거나 복잡하여 맥락을 이해 못한다 |
| 작은 생성형 모델(sLM:Small Language Model) 활용 | 크기가 커지지 않으면 어려운 맥락을 이해 못한다 |
Ranking을 위한 sLM과 distillation의 필요성
네이버는 LLM의 한계를 극복하기 위해 sLM(Small Language Model)과 distillation 기법을 활용했습니다.
1차 검토 내용
| 고민 | 1차 검토 | 2차 검토 |
| LLM이기 때문에 할 수 있는 것은 뭔가? | 복잡한 질의와 문서에 대한 정답셋을 만들 수 있다 | 피드백이 아닌 연관성 정답 데이터 labeling을 자동화하자 |
| 대화형일 필요가 있는가? | Ranking만 잘하면 된다 | Ranking외에 불필요한 단어 생성을 하지 말자 |
| 크고 느린 LLM이 꼭 필요한가? | Task-specific 한 모델이 필요하다 | sLM Ranker를 만들자 |
이를 통해 네이버는 롱테일 질의를 위해 sML을 도입하고 distillation(대규모 모델의 지식을 소규모 모델에 압축하는 기술) 작업을 하기로 결정합니다.
- sLM의 도입: sLM은 LLM의 주요 기능을 경량화한 모델로, 처리 속도는 빠르면서도 LLM 수준의 성능을 유지합니다.
- distillation: 대규모 LLM의 지식을 sLM에 압축하여 모델 크기를 줄이면서도 성능 손실을 최소화하는 기술입니다.
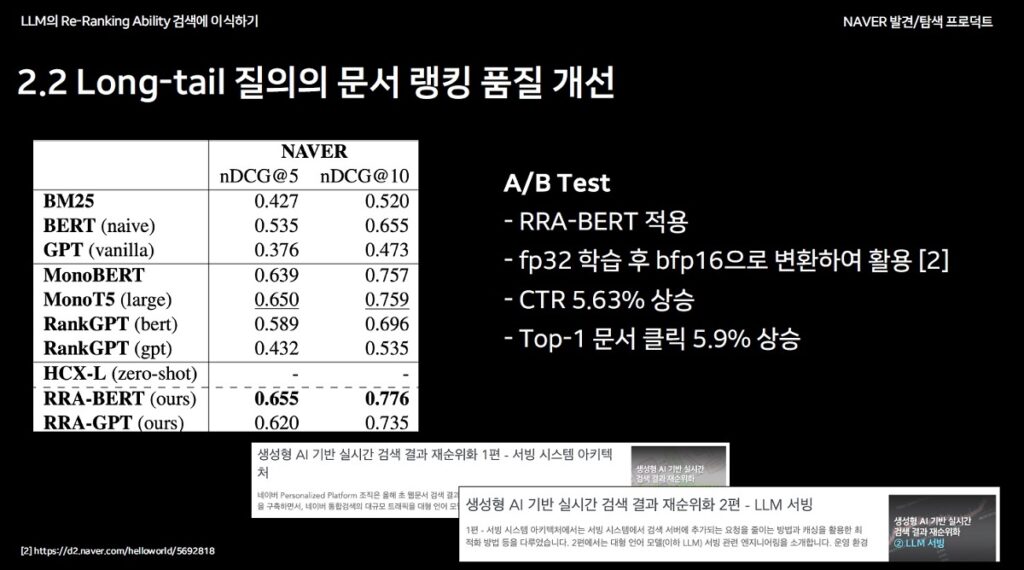
Long-tail 질의의 문서 랭킹 품질 개선
롱테일(long-tail) 질의는 자주 묻지 않는 복잡한 질문으로, 기존 검색 엔진이 처리하기 어려운 영역입니다. 네이버는 다음과 같은 방식을 통해 롱테일 질의의 검색 품질을 개선했습니다.
- BERT-style distillation (RRA-BERT): 구글 BERT 모델 기반의 distillation 기술을 활용하여 검색 문서의 관련성을 학습합니다. BERT는 구글이 개발한 자연어 처리 모델로, 문장 내 단어 간 관련성를 깊이 이해합니다.
- GPT-style distillation (RRA-GPT): GPT 모델 기반의 distillation 기술을 통해 관련성뿐 아니라 이유(reasoning)를 생성하며, 검색 결과의 품질을 한층 강화합니다. GPT는 OpenAI가 개발한 모델로, 언어 생성과 분석에 특화되어 있습니다.
네이버의 A/B 테스트 결과에 따르면 RRA-BERT 모델은 CTR(클릭률)을 5.63%, Top-1 문서 클릭률을 5.9% 상승시키며 검색 품질 향상에 기여했습니다.
최신성(Recency)을 반영한 검색 시스템
네이버는 대규모 언어 모델(LLM)을 검색 서비스에 도입하며, 비용과 성능 간의 균형을 맞추는 데 성공했습니다.
- LLM의 효율적 활용: LLM의 장점을 살리면서도 sLM과 distillation 기술을 활용해 경량화.
- 롱테일 질의와 최신성 강화: 롱테일 질의 처리와 최신 정보 반영을 위한 RRA-T 모델 도입.
- 사용자 중심의 검색 품질 개선: 사용자 피드백을 기반으로 Prompt를 설계해 최적화된 검색 결과 제공.
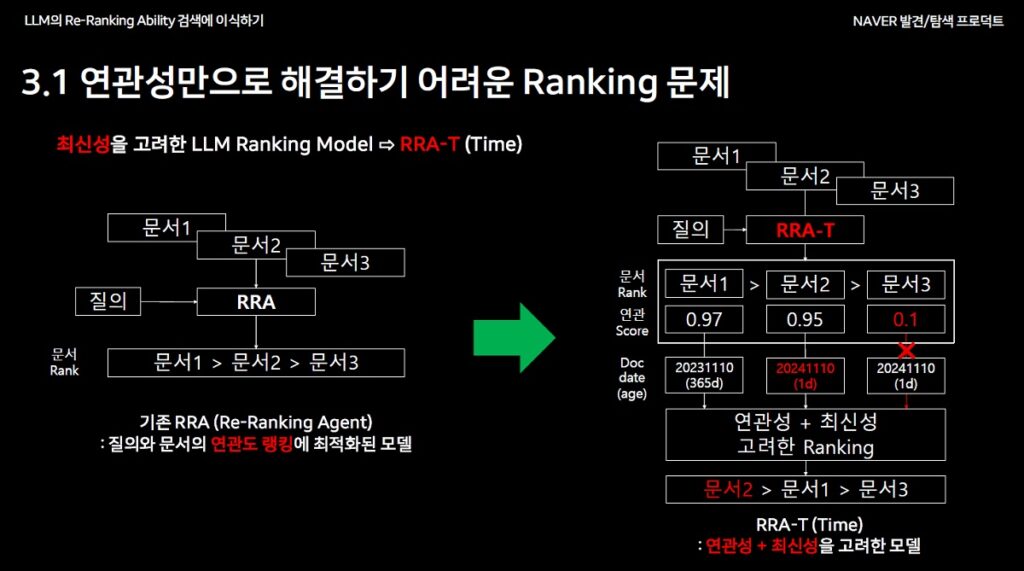
문제의식 #1 : 연관성 + 최신성 반영이 필요하다
- 롱테일 질의에서 기존 Re-Ranking 모델(RRA)의 한계점
- 연관성(Relevance) 기반 랭킹만으로는 문서 간의 최신성, 사용자 의도를 반영하기ㅁ 어렵다
- 예: 뉴스 기사나 시간 민감한 질의에서 최신 문서를 적합한 순서로 노출하지 못함
문제의식 #2 : 학습 데이터 보강이 필요하다
- Sigmoid Layer를 통해 Score를 출력할 수 있지만
- Pair-wise 방식으로 학습된 기존 데이터는 점수 분포가 고르지 않아 정밀한 Ranking이 어렵다
- Labeling 데이터 부족 문제로 인해 Ranking 품질이 저하된다
문제 해결을 위한 접근법
RRA에서 최신성을 반영하기 위한 개선 방안
- 최신성의 필요성 : 시간에 민감한 콘텐츠(뉴스, 트렌드)에서 최신성(Time)을 고려해야 함
- Ranking 개선 모델 검토 –> RRA-T 모델 : 연관성과 최신성을 모두 반영하는 모델을 설계하고 최신성을 랭킹에 반영하는 Re-Ranking 구조 필요
해결 방안
RRA-T 모델 도입
- 최신성 추가: 기존 RRA 모델에 최신성(Time)을 반영하고 개별 문서 단위로 평가하여 롱테일 질의의 랭킹 품질을 개선
- LLM 활용: LLM을 사용해 질의-문서 쌍(Q, D) 간의 Ranking 및 Score 생성. 사용자 피드백 로그를 분석해 최적의 Prompt 설계

학습 데이터 보강
- Score Labeling:
- 사용자 피드백 로그 로그를 활용해 LLM이 생성한 프롬프트 결과를 검증하고 최적의 프롬프트를 선정하기
- LLM으로 추가 라벨링 생성
| ◇ 왜 사용자의 클릭 데이터를 바로 RRA 학습 데이터로 사용하지 않나요? A. RRA가 Targeting 하는 Longtail 질의 특성상, 연관 있더라도 User가 클릭 하지 않는 문서들이 다수 존재 ⇨ False Negative Sample 이 될 수 있음 |

- Re-Ranking 데이터 정제:
- Abusing 방지를 위해 특정 질의에서 과도하게 클릭된 문서를 제거
- 노출된 문서 수가 N~M 범위에 있고, 클릭 문서가 노출 문서의 X%~Y% 비율을 만족하는 질의를 선별하여 신뢰도 높은 데이터를 학습에 활용

- 사용자 피드백 로그를 활용해 Prompt 선정하기
- Listwise(Ranking) + Pointwise(Scoring) vs Listwise(Ranking& Scoring) 중 Ranking과 Scoring 모두 Listwise(Ranking&Scoring)에서 우수함
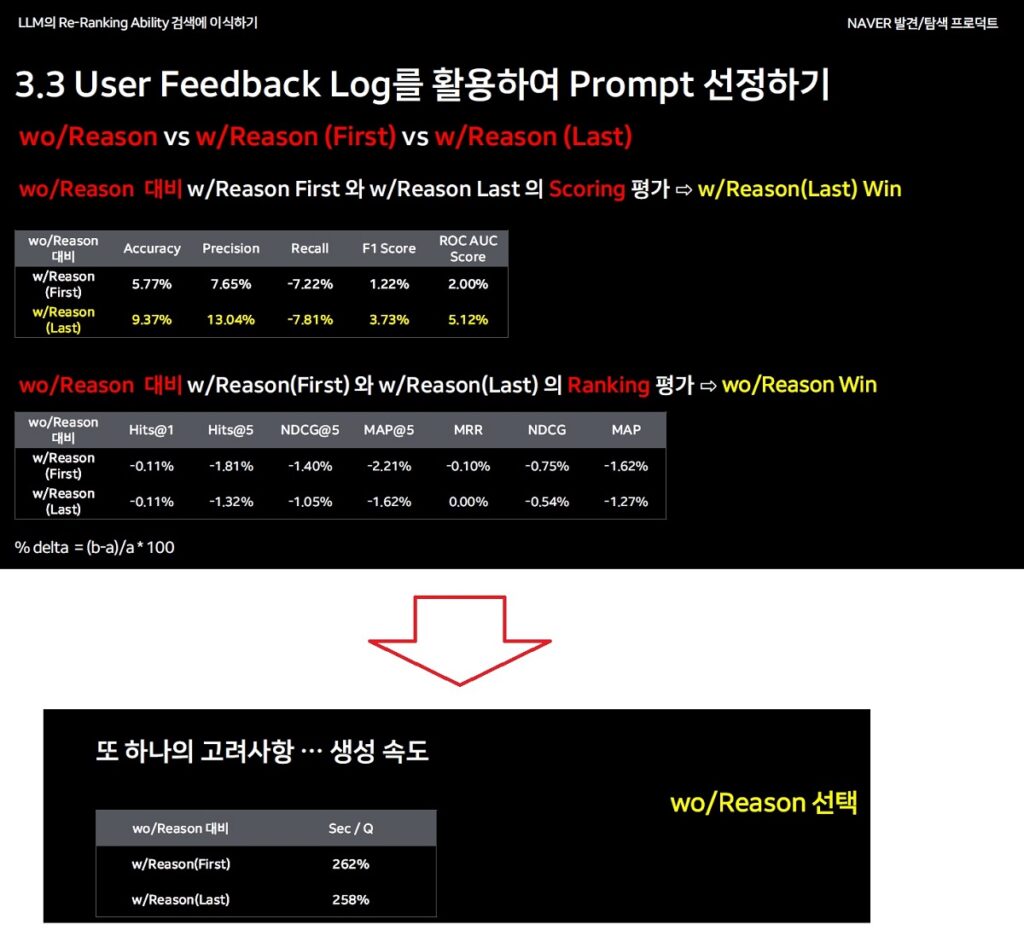
- wo/Reason vs w/Reason(First) vs w/Reason(Last) 중 scoring 평가 => w/Reason(Last)가 우수
- wo/Reason vs w/Reason(First) vs w/Reason(Last)의 ranking 평가 ==> wo/Reason이 우수
- 하지만 생성속도를 고려해볼때 wo/Reason을 최종적으로 선택함(wo/Reason의 생성 속도 대비 w/Reason(First)는 262%, w/Reason(Last)는 258% 더 오래 걸렸음)
선정된 Prompt로 생성한 데이터로 모델 학습
- 선정된 Prompt⇨사용자의 Feedback 경향성과 일치하는 Prompt
- Prompt + (Q ,D) ⇨LLM(HCX-L) ⇨Rank & Score 데이터 생성 (Train & Test Split)
- 모델학습 ==> RRA-T
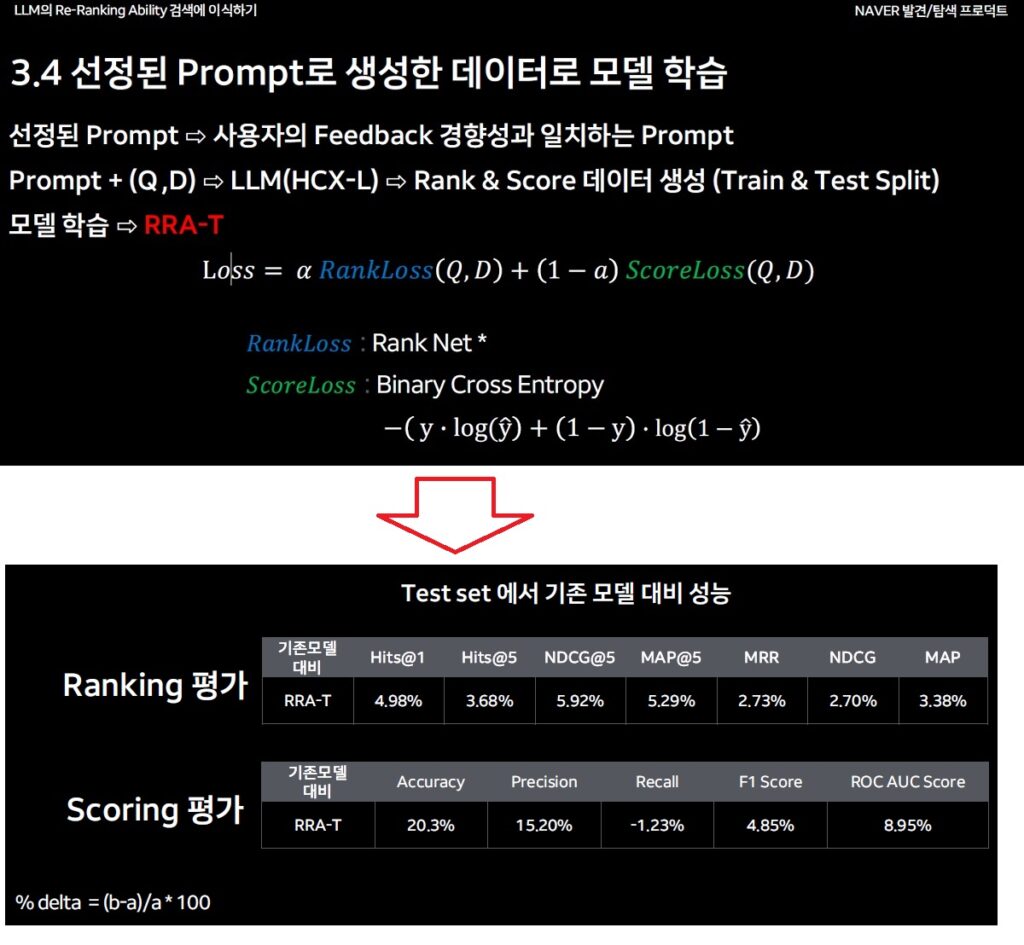
| 위 이미지의 손실 함수는 RRA-T 모델이 랭킹(Ranking)**과 점수화(Scoring)**를 동시에 최적화하도록 학습시키는 데 사용됨 – RankLoss는 문서 간 순서를 학습. – ScoreLoss는 문서의 적합도를 정확히 예측. – 𝛼 를 통해 두 손실 간의 균형을 조절하며, 특정 목적에 따라 비중을 다르게 설정 |
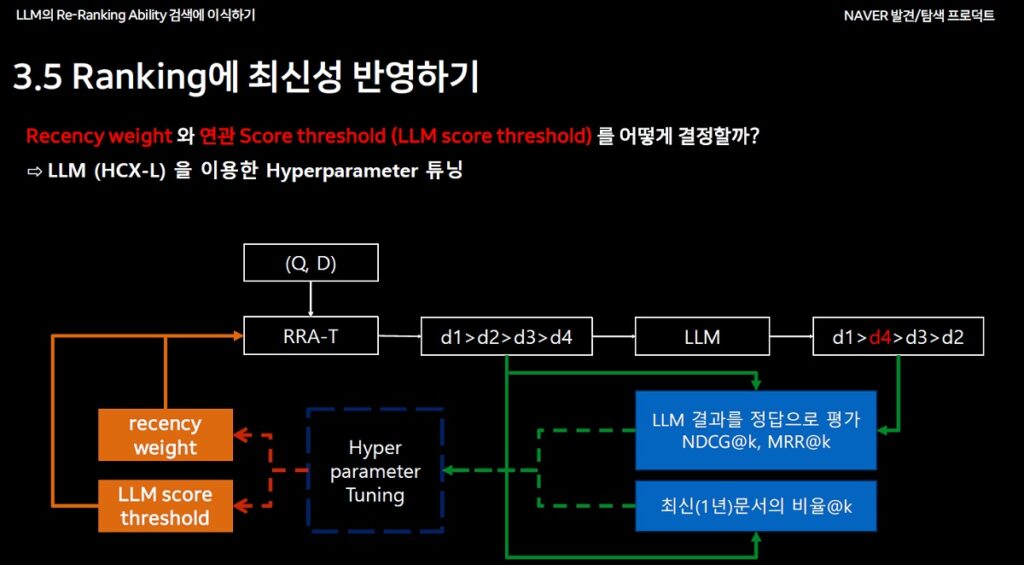
Ranking에 최신성 반영
- 최신성 가중치(Recency weight)와 관련성 점수 LLM Score threshold (LLM score threshold)를 튜닝해 랭킹 품질 극대화 ⇨ LLM (HCX-L) 을 이용한 Hyperparameter 튜닝
- LLM Score threshold(임계값) : x와 y
- 최신성 파라미터 : a, b, c, d
- 최신 문서를 많이 포함하면서도 성능 하락이 적은 parameter 선택
- ==> llm score threshold : x, recency weight : b
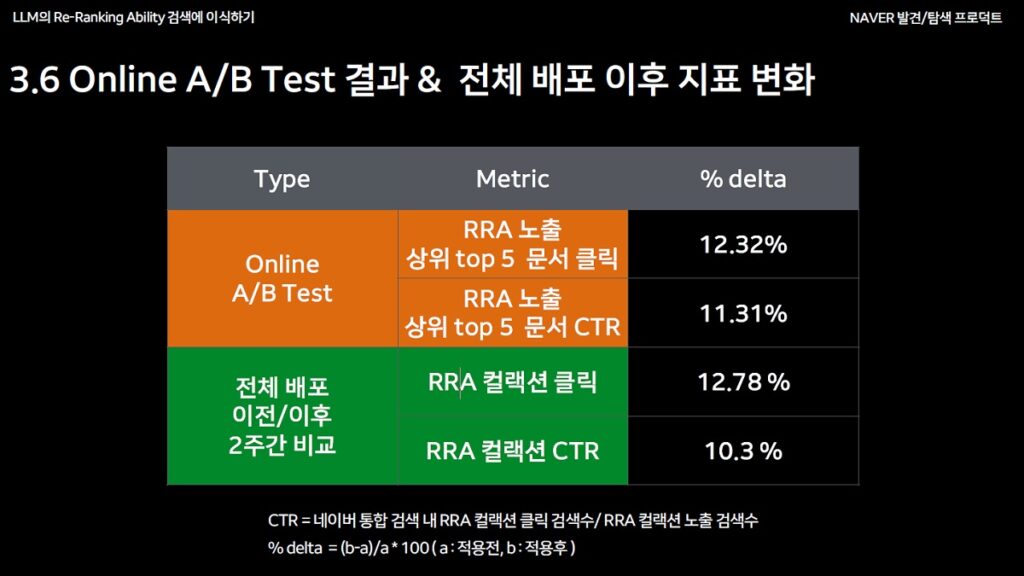
RRA-T 모델의 AB 테스트 결과
- 새로운 RRA-T 모델 도입으로 최신성과 연관성을 모두 반영
- 학습 데이터 강화로 랭킹 품질 향상
- 온라인 A/B 테스트 결과 전체적인 지수가 상승
용어 정리
- Ranker: 검색 엔진 또는 추천 시스템에서 문서나 결과의 순위를 결정하는 알고리즘 또는 모델을 의미합니다.
- LLM(Large Language Model): 대규모 데이터를 학습해 자연어를 이해하고 생성할 수 있는 언어 모델.
- sLM(Small Language Model): LLM의 성능을 간소화한 경량화된 모델.
- Distillation: 대규모 모델의 지식을 소규모 모델에 압축하는 기술.
- Prompt: LLM이 결과를 생성할 때 사용하는 입력 데이터.
- Re-ranking: 초기 검색 결과를 재정렬해 더 적합한 순서를 매기는 과정.
- BERT-style distillation (RRA-BERT): 구글의 BERT 모델을 기반으로 검색 문서의 관련성을 학습하는 기술.
- GPT-style distillation (RRA-GPT): OpenAI의 GPT 모델을 기반으로 문서 관련성 및 이유(reasoning)를 생성하는 기술.
관련 포스팅
거북이 미디어 전략 연구소장은 미디어의 온라인 수익화와 전략에 주요 관심을 가지고 있습니다.
저는 Publisher side에서 2015년부터 모바일과 PC 광고를 담당했습니다. 2022년부터 국내 포털을 담당하고 있습니다.
▲ 강의 이력
구글 디지털 성장 프로그램의 광고 워크샵 게스트 스피커(21년 6월)
구글 서치콘솔, 네이버 서치어드바이저, MS 웹마스터 도구 사용법(24년 8월 한국 언론진흥재단 미디어교육원)